这是 Linux 系统编程系列 中的第一篇, 在这个系列里面, 我想以这么个顺序来讲述每一篇的内容, 先是快速简单地了解一下 常见的使用方法, 即API如何使用, 接着再深入其中, 了解内核为API提供的帮助, 大致是 C标准库 → 系统调用 这么个学习路线.
时间的定义
首先要记住 计算机的起始时间 为 (格林威治时间)1970年1月1日0点, 被称作 GMT时间 是时区时间, 不过它是根据地球公转和自转来计算的, 不是特别准确. 在计算机世界中, 往往被称作 UTC时间, 它是以原子钟来计算时间, 简单来说就是 UTC时间 比 GMT时间要准确, 同时两个时间又恰好没有时差, 但是UTC时间又不是时区时间, 因此容易被人弄混.
获取时间
time() 秒
1 |
|
gettimeofday() 微秒
1 |
|
- 很多人说其性能不高 因为本质是系统调用 会频繁陷入内核
- 不过 在 x86_64下 采用了 vsyscall 并没有 陷入内核中
- 比 clock_gettime 性能高
- 兼容性不高(部分系统下 被弃用)
RDTSC 读取 TSC (Time Stamp Counter)
- 非特权指令 可以避免 用户态和内核态的开销
- 只能在 Intel 平台下使用
- 奔腾处理器引入了乱序执行, 可能会导致想测的指令在 RDTSC之外 执行, 如果有RDTSCP 最好用这个
- 当然如果没有的话, 那就只能用 cpuid指令 来保序
- CPU频率可能会被改变, 比如说开启了节能模式, 如果是比较新的Intel处理器 则可以采用 grep tsc /proc/cpuinfo,有constant_tsc 和 nonstop_tsc 也就足够了
- 各个CPU的核心中得TSC寄存器不一定同步, 同步的话开销太大, 用 RDTSC 指令没啥意义了
POSIX Timer 纳秒
1 |
|
- 当在 Intel x86_64 平台下获取 CLOCK_PROCESS_CPUTIME_ID 和 CLOCK_THREAD_CPUTIME_ID 本质上就是 用的 RDTSC 的 TSC(time stamp counter寄存器) 每个时间中断 + 1
- 总而言之, 大部分情况下 clock_gettime() 就够了, 如果要测纳秒上的结果, 再去用 RDTSC/RDTSCP指令.
可以看到 这几个函数 有一个 clock_id 的参数 这都属于 POSIX CLOCKS 中的内容.
CLOCK_ID
- CLOCK_REALTIME
- 系统真实时间 俗称墙上时间 可能会被用户修改, 受 NTP 影响
- CLOCK_MONOTONIC
- 与系统真实时间无关的时间, 单调时间, 受 NTP 影响
- CLOCK_PROCESS_CPUTIME_ID
- 进程所耗费时间
- CLOCK_THREAD_CPUTIME_ID
- 线程为单位耗费时间
- CLOCK_MONOTONIC_RAW
- 与 CLOCK_MONOTONIC 相似 不过不会被 NTP影响到其频率
- CLOCK_REALTIME_COARSE
- CLOCK_REALTIME 低精度版本 即以Tick为单位, 受 NTP 影响
- CLOCK_MONOTONIC_COARSE
- CLOCK_MONOTONIC 低精度版本 即以Tick为单位, 受 NTP 影响
- CLOCK_BOOTTIME
- 与 CLOCK_MONOTONIC 类似 但是会包含suspended时间
- CLOCK_REALTIME_ALARM
- 基于 RTC (Real Time Clock), 系统暂停也能运作
- CLOCK_BOOTTIME_ALARM
- 基于 RTC (Real Time Clock), 系统暂停也能运作
- CLOCK_TAI
- 原子钟时间 没有闰秒, 以上都受闰秒影响, 唯独这个不受.
原子秒 是各界大佬发现铯133基态的两个超精细能级之间跃迁所对应的辐射(电磁波)的9 192 631 770个周期持续的时间 非常稳定, 因此就拿它来定义 秒的概念. 物极必反, 原子秒非常精确,但与地球公转和自转存在时间差, 因此需要加入闰秒进行适当调整.
展示时间
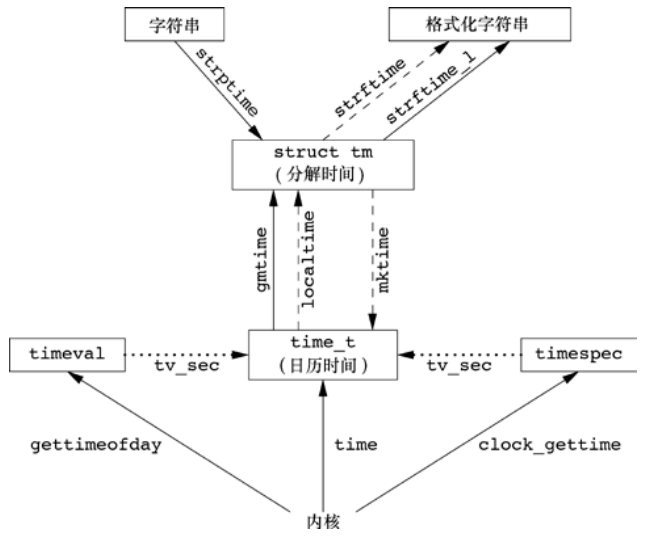
gmtime() 和 localtime()
1 |
|
mktime()
1 |
|
strftime()
1 | // 格式化 tm 结构体来打印时间 |
strptime()
1 |
|
附上 Unix 环境高级编程 中的一张图.
计时器
alarm()
sleep(), usleep() 都是用 SIGALRM实现
以秒为精度, 每个进程只能设置一个, 可以猜想到 PCB中只有一个 alarm(事实也是如此)
1 | // 到期则发出 SIGALRM(默认动作终止进程) |
setitimer()
也是用信号实现 不适合 多线程编程
1 | int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue); |
which 有 3种
- ITIMER_REAL 减少实际时间
- 发出 SIGALRM 信号
- ITIMER_VIRTUAL 减少进程所执行的时间(不包含进程调度时间)
- 发出 SIGVTALRM 信号
- ITIMER_PROF 减少进程所执行时间和进程调度所用时间
- 发出 SIGPROF 信号
timerfd_create()
将时间当做文件描述符, 在超时的时候, 文件变为可读, 适于多线程编程, 能很好融入 poll, epoll
1 | int timerfd_create(int clockid, int flags); |
硬件的本领
可以总结一下, 硬件有很多种, 有关时间的硬件无非要么提供时间中断功能, 要么提供了存储时间供用户读取的功能, 要么两者皆有.
- RTC(Real Time Clock) 实时时钟
- 顾名思义 记录当前时间, 同时断电的时候 主板有个电池, 维持正确的时间, 精度到秒
- 既可以存储 LCT 也可以存储 UTC 凭借系统的配置文件进行配置
- TSC(Time Stamp Counter)
- 就是上面讲到的 RDTSC 汇编指令所度的硬件, 只存在于 Intel 处理器, 每个Tick 都会 加 1, 即每次时钟中断都会 + 1, 纳秒级别时间精度.
还有更多的硬件, 就不一一解释了, 只要记住 硬件主要是 提供中断 和 存储时间的能力, 哪怕上层函数提供的时间精度再精细, 本质上也是因为硬件的计时单位精度提高了.
Linux 中的时间
这一小节, 将讲解 Linux 0.12 中是如何实现时间系统的.
系统时间
顾名思义, 就是维护系统时间的, 前面提到过 RTC 有一块电池, 始终保持系统时间, Linux 在 time_init 函数那, 会读取 RTC 硬件上的信息, 并将其初始化到 startup_time, 此后直到重启系统, 都不会再去读取 RTC了.
1 | // 内核中还会有这个宏, 来维护当前时间 每个jiffies 为一个Tick |
每一次 发起时钟中断, 内核会调用到 do_timer() 这一函数
1 | /* |
看完上面, 细心地观众可能会在想 jiffies 没有++啊? 那怎么维护 CURRENT_TIME 这个宏呢?
其实是在 系统调用的时候, 已经加了.
1 | timer_interrupt: |
以上都是最基础的 Linux 0.12 版本的实现, 至于其他 clock_gettime 上面也提到过, 在大多数情况直接用的是 RDTSC 这一汇编指令.
计时器实现
alarm() 实现
1 | // 一个系统调用 设置PCB的 alarm数值 |
这里先暂时略过 信号的工作原理, 等有机会再讲, 现在只要知道它发送了 SIGALARM 信号就行了.
动态 Timer
其实就是内核里面用到的Timer, 也是用户态计时器的基础.
这可以理解为最早期的时间轮算法, 不过在后期 Linux 使用了 Hierarchy 时间轮, 它本身是按照 时/分/秒 分为三个层级, 每个层级又根据 24/60/60 来分桶, 每次时钟中断的时候, 就将到期的移除, 且进行触发通知, Hierarchy 时间轮的 添加删除触发都是O(1), 但是维护起来非常费时, 比如当 分 走回0的时候, 就需要对 时 做移动, 通常我们的 Timer 达不到 60个那么多, 所以比较耗时.
也因此, Linux 采用的是 将 jiffies 分为 5个部分, Linux中称作 Timer Vector, 用来进行索引, 也有上面处理的缺点, 会带来不确定的延时.
1 | // 此为最早期的 时间轮, 并非是 Hierarchy 时间轮 |
可以看出 最多只能支持到 64 个 Timer, 每次发生时钟中断的时候 就遍历一下 timer_list.
间隔 Timer setitimer()
- ITIMER_REAL 实际时间
- 因为是实际时间 可以直接用 内核中的 Timer实现
- ITIMER_VIRTUAL 进程真实执行时间
- 由于参照的是进程时间, 要判断处于内核态还是用户态, 再修改相应数值 比如 utime, stime
- ITIMER_PROF 进程执行时间+进程调度时间
- 和上面一样 也要考虑到当前内核态还是用户态
POSIX Timer
低精度版本 时间轮
这其实就是上面 讲的 与 CLOCK_ID 相关的一类的接口, 其中 CLOCK_REALTIME 与 CLOCK_MONOTONIC 实现起来较为简单, 直接建立在 内核动态 Timer之上, 以 Tick 为单位.
然后 CLOCK_PROCESS_CPUTIME_ID 和 CLOCK_THREAD_CPUTIME_ID 这两个是和进程线程相关, 理所当然的是要在 PCB 下进行维护, Linux 做法是在PCB 下面加两个数组, 其中每个数组又做成了链表的形式, 有点像桶, 来维护 PROCESS 和 THREAD 的CPU Timer.
现在有了高精度版本的计时器, 基本上就只有内核和一些旧的驱动程序还在用了.
高精度版本 Hrtimer
要想提高精度, 自然要先将硬件上的HZ提高, 同时又不能太高, 高过1000的话, 时钟中断太频繁了, 性能会下降.
由于之前那套时间轮算法, 调整的过程 必然会有开销(因为你要重新排列位置), 因此引入了一个新的计时器 Hrtimer.
Hrtimer 的实现还是很简单的
- 用红黑树以到期时间为key进行排序
- 猜测使用红黑树的原因是 内核里面本身就有, 而且测试后特别好
- 不用 jiffies 为计时单位, jiffies = 10ms 精度不够, 以 纳秒为计时单位
在 多处理器的情况下, 每个CPU 都要维护 两个数据结构, 一个为 Monotonic 另一个是 Real time.
在高精度计时器中, 是直接有硬件计时器进行中断触发, 而不再是使用 Tick, 不过始终有误差, 因为始终还是通过中断机制去修改 Hrtimer 的红黑树嘛, 只不过 Hrtimer 的中断处理函数只醉心于 计时, 那原先的时钟中断所做的进程调度之类的事情, 则是由 Hrtimer 开一个计时器, 然后设置好间隔的 Tick, 最后设置 计时回调函数, 当时间到了, 就到计时回调函数那处理 进程调度.
换一句话说就是 Hrtimer 开了一个计时器 模拟了 时钟中断.
总结
经过上面的洗礼,相信读者已经对 Linux 下的时间编程原理有了一个新的认识, 用起来就按需要的精度来选择, 原理 无非就是 将时间分为5个部分 做成一个时间轮 或者 用红黑树将到期时间进行排序, 本质上都离不开中断机制.