TigerShrimp 内部有个简单的 Interpreter,用以直接执行 bytecode,执行每一条 Instruction时,会记录当前的 pc (二元组,记录函数索引和指令索引,不然指令索引可能重复),是否为热路径,若为热路径,则会执行 record 流程,记录每一条执行的指令。(通常记录循环,循环有回边,记录执行次数,执行次数大于一阈值,则认为是热路径)。
在上面中,我们手动删除了 a 和 b ,理应进行释放,但由于 a 和 b 互相构成了循环引用,导致其引用计数总是不为0,进而造成内存泄漏,而 CPython 对其解决方法也极其简单,就是将所有可能造成循环引用的对象,构成一个双向链表进行扫描,从 root object 出发进行扫描 - 清除,无法到达的对象就是可释放的对象,普通的对象直接采用引用计数去释放,简单快捷。
怎么去验证以上结论呢?我们可以用反证法,当 del a 和 del b 后,再调用 gc.collect() 查看其是否能被回收到,如果能回收到,说明在此时引用计数已经失效。
[<__main__.A object at 0x10adefc10>, <__main__.B object at 0x10adeff70>, {'b': <__main__.B object at 0x10adeff70>}, {'a': <__main__.A object at 0x10adefc10>}]
/* GC information is stored BEFORE the object structure. */ typedefstruct { // Pointer to next object in the list. // 0 means the object is not tracked uintptr_t _gc_next;
// Pointer to previous object in the list. // Lowest two bits are used for flags documented later. uintptr_t _gc_prev; } PyGC_Head;
// Lowest bit of _gc_next is used for flags only in GC. // But it is always 0 for normal code. #define _PyGCHead_NEXT(g) ((PyGC_Head*)(g)->_gc_next) #define _PyGCHead_SET_NEXT(g, p) _Py_RVALUE((g)->_gc_next = (uintptr_t)(p))
// Lowest two bits of _gc_prev is used for _PyGC_PREV_MASK_* flags. #define _PyGCHead_PREV(g) ((PyGC_Head*)((g)->_gc_prev & _PyGC_PREV_MASK)) #define _PyGCHead_SET_PREV(g, p) do { \ assert(((uintptr_t)p & ~_PyGC_PREV_MASK) == 0); \ (g)->_gc_prev = ((g)->_gc_prev & ~_PyGC_PREV_MASK) \ | ((uintptr_t)(p)); \ } while (0)
static Py_ssize_t gc_collect_main(PyThreadState *tstate, int generation, Py_ssize_t *n_collected, Py_ssize_t *n_uncollectable, int nofail) { int i; Py_ssize_t m = 0; /* # objects collected */ Py_ssize_t n = 0; /* # unreachable objects that couldn't be collected */ PyGC_Head *young; /* the generation we are examining */ PyGC_Head *old; /* next older generation */ PyGC_Head unreachable; /* non-problematic unreachable trash */ PyGC_Head finalizers; /* objects with, & reachable from, __del__ */ PyGC_Head *gc; _PyTime_t t1 = 0; /* initialize to prevent a compiler warning */ GCState *gcstate = &tstate->interp->gc;
// 将更老的一代的 count + 1 从而让之后能执行到后续的垃圾回收 if (generation+1 < NUM_GENERATIONS) gcstate->generations[generation+1].count += 1; // 当前代和比当前代更年轻的计数重置,因为我们会将[0, 当前代]全部处理完 for (i = 0; i <= generation; i++) gcstate->generations[i].count = 0;
// 将更年轻的代归到当前代的链表上 for (i = 0; i < generation; i++) { gc_list_merge(GEN_HEAD(gcstate, i), GEN_HEAD(gcstate, generation)); }
// young = [0, 当前代] young = GEN_HEAD(gcstate, generation); if (generation < NUM_GENERATIONS-1) // 当当前为第1代则old为第2代,当当前为第0代则old为第1 old = GEN_HEAD(gcstate, generation+1); else // 说明当前为第2代,则old也为第2代 old = young;
CPython 的GC是 Stop The World 的,哪怕它已经很尽力用分代的方式去减少GC的损耗。是否可以将其改进为渐进的方式?我目前的想法是在容器操作时,进行 Barrier 操作,维护一个中间态,使得前面的扫描过程是可渐进的,最后处理垃圾的时候再停下来一次性处理完,减少停止的时间。但这个思路貌似不行,原因是根集是不确定的。
>>> print(float.__call__) <method-wrapper '__call__' of typeobject at 0x103f65d70> >>> print(int.__call__) <method-wrapper '__call__' of typeobject at 0x103f67f90>
>>> print(type.__call__) <slot wrapper '__call__' of 'type' objects>
PyDoc_STRVAR(object_doc, "object()\n--\n\n" "The base class of the class hierarchy.\n\n" "When called, it accepts no arguments and returns a new featureless\n" "instance that has no instance attributes and cannot be given any.\n");
// floatinfo 浮点数一些信息 PyDoc_STRVAR(floatinfo__doc__, "sys.float_info\n\ \n\ A named tuple holding information about the float type. It contains low level\n\ information about the precision and internal representation. Please study\n\ your system's :file:`float.h` for more information."); static PyStructSequence_Field floatinfo_fields[] = { {"max", "DBL_MAX -- maximum representable finite float"}, {"max_exp", "DBL_MAX_EXP -- maximum int e such that radix**(e-1) " "is representable"}, {"max_10_exp", "DBL_MAX_10_EXP -- maximum int e such that 10**e " "is representable"}, {"min", "DBL_MIN -- Minimum positive normalized float"}, {"min_exp", "DBL_MIN_EXP -- minimum int e such that radix**(e-1) " "is a normalized float"}, {"min_10_exp", "DBL_MIN_10_EXP -- minimum int e such that 10**e is " "a normalized"}, {"dig", "DBL_DIG -- maximum number of decimal digits that " "can be faithfully represented in a float"}, {"mant_dig", "DBL_MANT_DIG -- mantissa digits"}, {"epsilon", "DBL_EPSILON -- Difference between 1 and the next " "representable float"}, {"radix", "FLT_RADIX -- radix of exponent"}, {"rounds", "FLT_ROUNDS -- rounding mode used for arithmetic " "operations"}, {0} };
static PyObject * float_new_impl(PyTypeObject *type, PyObject *x) { if (type != &PyFloat_Type) { if (x == NULL) { x = _PyLong_GetZero(); } return float_subtype_new(type, x); /* Wimp out */ }
if (x == NULL) { return PyFloat_FromDouble(0.0); } /* If it's a string, but not a string subclass, use PyFloat_FromString. */ if (PyUnicode_CheckExact(x)) return PyFloat_FromString(x); return PyNumber_Float(x); }
r = PyObject_RichCompareBool(vv, ww, op); if (r < 0) goto Error; result = PyBool_FromLong(r); Error: Py_XDECREF(vv); Py_XDECREF(ww); return result; } } /* else if (PyLong_Check(w)) */
else/* w isn't float or int */ goto Unimplemented;
Compare: switch (op) { case Py_EQ: r = i == j; break; case Py_NE: r = i != j; break; case Py_LE: r = i <= j; break; case Py_GE: r = i >= j; break; case Py_LT: r = i < j; break; case Py_GT: r = i > j; break; } return PyBool_FromLong(r);
intluaV_equalobj(lua_State *L, const TValue *t1, const TValue *t2) { const TValue *tm; if (ttype(t1) != ttype(t2)) { /* not the same variant? */ if (ttnov(t1) != ttnov(t2) || ttnov(t1) != LUA_TNUMBER) return0; /* only numbers can be equal with different variants */ else { /* two numbers with different variants */ lua_Integer i1, i2; /* compare them as integers */ return (tointeger(t1, &i1) && tointeger(t2, &i2) && i1 == i2); } }
/* Force our slaves to resync with us as well. They may hopefully be able * to partially resync with us, but we can notify the replid change. */ disconnectSlaves(); cancelReplicationHandshake(0); /* Before destroying our master state, create a cached master using * our own parameters, to later PSYNC with the new master. */ if (was_master) { replicationDiscardCachedMaster(); replicationCacheMasterUsingMyself(); }
voidsyncWithMaster(connection *conn) { char tmpfile[256], *err = NULL; int dfd = -1, maxtries = 5; int psync_result;
/* If this event fired after the user turned the instance into a master * with SLAVEOF NO ONE we must just return ASAP. */ if (server.repl_state == REPL_STATE_NONE) { connClose(conn); return; }
/* Check for errors in the socket: after a non blocking connect() we * may find that the socket is in error state. */ if (connGetState(conn) != CONN_STATE_CONNECTED) { serverLog(LL_WARNING,"Error condition on socket for SYNC: %s", connGetLastError(conn)); goto error; }
/* Send a PING to check the master is able to reply without errors. */ if (server.repl_state == REPL_STATE_CONNECTING) { serverLog(LL_NOTICE,"Non blocking connect for SYNC fired the event."); /* Delete the writable event so that the readable event remains * registered and we can wait for the PONG reply. */ connSetReadHandler(conn, syncWithMaster); connSetWriteHandler(conn, NULL); server.repl_state = REPL_STATE_RECEIVE_PING_REPLY; /* Send the PING, don't check for errors at all, we have the timeout * that will take care about this. */ err = sendCommand(conn,"PING",NULL); if (err) goto write_error; return; }
/* Receive the PONG command. */ if (server.repl_state == REPL_STATE_RECEIVE_PING_REPLY) { err = receiveSynchronousResponse(conn);
/* We accept only two replies as valid, a positive +PONG reply * (we just check for "+") or an authentication error. * Note that older versions of Redis replied with "operation not * permitted" instead of using a proper error code, so we test * both. */ if (err[0] != '+' && strncmp(err,"-NOAUTH",7) != 0 && strncmp(err,"-NOPERM",7) != 0 && strncmp(err,"-ERR operation not permitted",28) != 0) { serverLog(LL_WARNING,"Error reply to PING from master: '%s'",err); sdsfree(err); goto error; } else { serverLog(LL_NOTICE, "Master replied to PING, replication can continue..."); } sdsfree(err); err = NULL; server.repl_state = REPL_STATE_SEND_HANDSHAKE; }
握手阶段主要是进行密码验证,将 Slave 的 IP 和 PORT 传给 Master 方便查询,同时告诉 Master 我当前的能力,比如 EOF 为我支持 无盘传输 , psync2 表示支持部分同步。
if (server.repl_state == REPL_STATE_SEND_HANDSHAKE) { /* AUTH with the master if required. */ if (server.masterauth) { char *args[3] = {"AUTH",NULL,NULL}; size_t lens[3] = {4,0,0}; int argc = 1; if (server.masteruser) { args[argc] = server.masteruser; lens[argc] = strlen(server.masteruser); argc++; } args[argc] = server.masterauth; lens[argc] = sdslen(server.masterauth); argc++; err = sendCommandArgv(conn, argc, args, lens); if (err) goto write_error; }
/* Set the slave port, so that Master's INFO command can list the * slave listening port correctly. */ { int port; if (server.slave_announce_port) port = server.slave_announce_port; elseif (server.tls_replication && server.tls_port) port = server.tls_port; else port = server.port; sds portstr = sdsfromlonglong(port); err = sendCommand(conn,"REPLCONF", "listening-port",portstr, NULL); sdsfree(portstr); if (err) goto write_error; }
/* Set the slave ip, so that Master's INFO command can list the * slave IP address port correctly in case of port forwarding or NAT. * Skip REPLCONF ip-address if there is no slave-announce-ip option set. */ if (server.slave_announce_ip) { err = sendCommand(conn,"REPLCONF", "ip-address",server.slave_announce_ip, NULL); if (err) goto write_error; }
/* Inform the master of our (slave) capabilities. * * EOF: supports EOF-style RDB transfer for diskless replication. * PSYNC2: supports PSYNC v2, so understands +CONTINUE <new repl ID>. * * The master will ignore capabilities it does not understand. */ err = sendCommand(conn,"REPLCONF", "capa","eof","capa","psync2",NULL); if (err) goto write_error;
/* Try a partial resynchonization. If we don't have a cached master * slaveTryPartialResynchronization() will at least try to use PSYNC * to start a full resynchronization so that we get the master replid * and the global offset, to try a partial resync at the next * reconnection attempt. */ if (server.repl_state == REPL_STATE_SEND_PSYNC) { if (slaveTryPartialResynchronization(conn,0) == PSYNC_WRITE_ERROR) { err = sdsnew("Write error sending the PSYNC command."); abortFailover("Write error to failover target"); goto write_error; } server.repl_state = REPL_STATE_RECEIVE_PSYNC_REPLY; return; }
psync_result = slaveTryPartialResynchronization(conn,1); if (psync_result == PSYNC_WAIT_REPLY) return; /* Try again later... */
/* Check the status of the planned failover. We expect PSYNC_CONTINUE, * but there is nothing technically wrong with a full resync which * could happen in edge cases. */ if (server.failover_state == FAILOVER_IN_PROGRESS) { if (psync_result == PSYNC_CONTINUE || psync_result == PSYNC_FULLRESYNC) { clearFailoverState(); } else { abortFailover("Failover target rejected psync request"); return; } }
/* If the master is in an transient error, we should try to PSYNC * from scratch later, so go to the error path. This happens when * the server is loading the dataset or is not connected with its * master and so forth. */ if (psync_result == PSYNC_TRY_LATER) goto error;
/* Note: if PSYNC does not return WAIT_REPLY, it will take care of * uninstalling the read handler from the file descriptor. */
if (psync_result == PSYNC_CONTINUE) { serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization."); if (server.supervised_mode == SUPERVISED_SYSTEMD) { redisCommunicateSystemd("STATUS=MASTER <-> REPLICA sync: Partial Resynchronization accepted. Ready to accept connections in read-write mode.\n"); } return; }
/* PSYNC failed or is not supported: we want our slaves to resync with us * as well, if we have any sub-slaves. The master may transfer us an * entirely different data set and we have no way to incrementally feed * our slaves after that. */ disconnectSlaves(); /* Force our slaves to resync with us as well. */ freeReplicationBacklog(); /* Don't allow our chained slaves to PSYNC. */
/* Fall back to SYNC if needed. Otherwise psync_result == PSYNC_FULLRESYNC * and the server.master_replid and master_initial_offset are * already populated. */ if (psync_result == PSYNC_NOT_SUPPORTED) { serverLog(LL_NOTICE,"Retrying with SYNC..."); if (connSyncWrite(conn,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING,"I/O error writing to MASTER: %s", strerror(errno)); goto error; } }
通过 RDB 文件传输,则先创建临时文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* Prepare a suitable temp file for bulk transfer */ if (!useDisklessLoad()) { while(maxtries--) { snprintf(tmpfile,256, "temp-%d.%ld.rdb",(int)server.unixtime,(longint)getpid()); dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644); if (dfd != -1) break; sleep(1); } if (dfd == -1) { serverLog(LL_WARNING,"Opening the temp file needed for MASTER <-> REPLICA synchronization: %s",strerror(errno)); goto error; } server.repl_transfer_tmpfile = zstrdup(tmpfile); server.repl_transfer_fd = dfd; }
/* Writing half */ if (!read_reply) { /* Initially set master_initial_offset to -1 to mark the current * master replid and offset as not valid. Later if we'll be able to do * a FULL resync using the PSYNC command we'll set the offset at the * right value, so that this information will be propagated to the * client structure representing the master into server.master. */ server.master_initial_offset = -1;
if (server.cached_master) { psync_replid = server.cached_master->replid; snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1); serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset); } else { serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)"); psync_replid = "?"; memcpy(psync_offset,"-1",3); }
/* Issue the PSYNC command, if this is a master with a failover in * progress then send the failover argument to the replica to cause it * to become a master */ if (server.failover_state == FAILOVER_IN_PROGRESS) { reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,"FAILOVER",NULL); } else { reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,NULL); }
if (reply != NULL) { serverLog(LL_WARNING,"Unable to send PSYNC to master: %s",reply); sdsfree(reply); connSetReadHandler(conn, NULL); return PSYNC_WRITE_ERROR; } return PSYNC_WAIT_REPLY; }
/* Reading half */ reply = receiveSynchronousResponse(conn); if (sdslen(reply) == 0) { /* The master may send empty newlines after it receives PSYNC * and before to reply, just to keep the connection alive. */ sdsfree(reply); return PSYNC_WAIT_REPLY; }
connSetReadHandler(conn, NULL);
if (!strncmp(reply,"+FULLRESYNC",11)) { char *replid = NULL, *offset = NULL;
/* FULL RESYNC, parse the reply in order to extract the replid * and the replication offset. */ replid = strchr(reply,' '); if (replid) { replid++; offset = strchr(replid,' '); if (offset) offset++; } if (!replid || !offset || (offset-replid-1) != CONFIG_RUN_ID_SIZE) { serverLog(LL_WARNING, "Master replied with wrong +FULLRESYNC syntax."); /* This is an unexpected condition, actually the +FULLRESYNC * reply means that the master supports PSYNC, but the reply * format seems wrong. To stay safe we blank the master * replid to make sure next PSYNCs will fail. */ memset(server.master_replid,0,CONFIG_RUN_ID_SIZE+1); } else { memcpy(server.master_replid, replid, offset-replid-1); server.master_replid[CONFIG_RUN_ID_SIZE] = '\0'; server.master_initial_offset = strtoll(offset,NULL,10); serverLog(LL_NOTICE,"Full resync from master: %s:%lld", server.master_replid, server.master_initial_offset); } /* We are going to full resync, discard the cached master structure. */ replicationDiscardCachedMaster(); sdsfree(reply); return PSYNC_FULLRESYNC; }
if (!strncmp(reply,"+CONTINUE",9)) { /* Partial resync was accepted. */ serverLog(LL_NOTICE, "Successful partial resynchronization with master.");
/* Check the new replication ID advertised by the master. If it * changed, we need to set the new ID as primary ID, and set or * secondary ID as the old master ID up to the current offset, so * that our sub-slaves will be able to PSYNC with us after a * disconnection. */ char *start = reply+10; char *end = reply+9; while(end[0] != '\r' && end[0] != '\n' && end[0] != '\0') end++; if (end-start == CONFIG_RUN_ID_SIZE) { char new[CONFIG_RUN_ID_SIZE+1]; memcpy(new,start,CONFIG_RUN_ID_SIZE); new[CONFIG_RUN_ID_SIZE] = '\0';
if (strcmp(new,server.cached_master->replid)) { /* Master ID changed. */ serverLog(LL_WARNING,"Master replication ID changed to %s",new);
/* Set the old ID as our ID2, up to the current offset+1. */ memcpy(server.replid2,server.cached_master->replid, sizeof(server.replid2)); server.second_replid_offset = server.master_repl_offset+1;
/* Update the cached master ID and our own primary ID to the * new one. */ memcpy(server.replid,new,sizeof(server.replid)); memcpy(server.cached_master->replid,new,sizeof(server.replid));
/* Disconnect all the sub-slaves: they need to be notified. */ disconnectSlaves(); } }
/* Setup the replication to continue. */ sdsfree(reply); replicationResurrectCachedMaster(conn);
/* If this instance was restarted and we read the metadata to * PSYNC from the persistence file, our replication backlog could * be still not initialized. Create it. */ if (server.repl_backlog == NULL) createReplicationBacklog(); return PSYNC_CONTINUE; }
/* If we reach this point we received either an error (since the master does * not understand PSYNC or because it is in a special state and cannot * serve our request), or an unexpected reply from the master. * * Return PSYNC_NOT_SUPPORTED on errors we don't understand, otherwise * return PSYNC_TRY_LATER if we believe this is a transient error. */
if (!strncmp(reply,"-NOMASTERLINK",13) || !strncmp(reply,"-LOADING",8)) { serverLog(LL_NOTICE, "Master is currently unable to PSYNC " "but should be in the future: %s", reply); sdsfree(reply); return PSYNC_TRY_LATER; }
if (strncmp(reply,"-ERR",4)) { /* If it's not an error, log the unexpected event. */ serverLog(LL_WARNING, "Unexpected reply to PSYNC from master: %s", reply); } else { serverLog(LL_NOTICE, "Master does not support PSYNC or is in " "error state (reply: %s)", reply); } sdsfree(reply); replicationDiscardCachedMaster(); return PSYNC_NOT_SUPPORTED; }
/* Static vars used to hold the EOF mark, and the last bytes received * from the server: when they match, we reached the end of the transfer. */ staticchar eofmark[CONFIG_RUN_ID_SIZE]; staticchar lastbytes[CONFIG_RUN_ID_SIZE]; staticint usemark = 0;
/* If repl_transfer_size == -1 we still have to read the bulk length * from the master reply. */ if (server.repl_transfer_size == -1) { if (connSyncReadLine(conn,buf,1024,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING, "I/O error reading bulk count from MASTER: %s", strerror(errno)); goto error; }
if (buf[0] == '-') { serverLog(LL_WARNING, "MASTER aborted replication with an error: %s", buf+1); goto error; } elseif (buf[0] == '\0') { /* At this stage just a newline works as a PING in order to take * the connection live. So we refresh our last interaction * timestamp. */ server.repl_transfer_lastio = server.unixtime; return; } elseif (buf[0] != '$') { serverLog(LL_WARNING,"Bad protocol from MASTER, the first byte is not '$' (we received '%s'), are you sure the host and port are right?", buf); goto error; }
/* There are two possible forms for the bulk payload. One is the * usual $<count> bulk format. The other is used for diskless transfers * when the master does not know beforehand the size of the file to * transfer. In the latter case, the following format is used: * * $EOF:<40 bytes delimiter> * * At the end of the file the announced delimiter is transmitted. The * delimiter is long and random enough that the probability of a * collision with the actual file content can be ignored. */ if (strncmp(buf+1,"EOF:",4) == 0 && strlen(buf+5) >= CONFIG_RUN_ID_SIZE) { usemark = 1; memcpy(eofmark,buf+5,CONFIG_RUN_ID_SIZE); memset(lastbytes,0,CONFIG_RUN_ID_SIZE); /* Set any repl_transfer_size to avoid entering this code path * at the next call. */ server.repl_transfer_size = 0; serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF %s", use_diskless_load? "to parser":"to disk"); } else { usemark = 0; server.repl_transfer_size = strtol(buf+1,NULL,10); serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: receiving %lld bytes from master %s", (longlong) server.repl_transfer_size, use_diskless_load? "to parser":"to disk"); } return; }
if (!use_diskless_load) { /* Read the data from the socket, store it to a file and search * for the EOF. */ if (usemark) { readlen = sizeof(buf); } else { left = server.repl_transfer_size - server.repl_transfer_read; readlen = (left < (signed)sizeof(buf)) ? left : (signed)sizeof(buf); }
nread = connRead(conn,buf,readlen); if (nread <= 0) { if (connGetState(conn) == CONN_STATE_CONNECTED) { /* equivalent to EAGAIN */ return; } serverLog(LL_WARNING,"I/O error trying to sync with MASTER: %s", (nread == -1) ? strerror(errno) : "connection lost"); cancelReplicationHandshake(1); return; } atomicIncr(server.stat_net_input_bytes, nread);
/* When a mark is used, we want to detect EOF asap in order to avoid * writing the EOF mark into the file... */ int eof_reached = 0;
if (usemark) { /* Update the last bytes array, and check if it matches our * delimiter. */ if (nread >= CONFIG_RUN_ID_SIZE) { memcpy(lastbytes,buf+nread-CONFIG_RUN_ID_SIZE, CONFIG_RUN_ID_SIZE); } else { int rem = CONFIG_RUN_ID_SIZE-nread; memmove(lastbytes,lastbytes+nread,rem); memcpy(lastbytes+rem,buf,nread); } if (memcmp(lastbytes,eofmark,CONFIG_RUN_ID_SIZE) == 0) eof_reached = 1; }
/* Update the last I/O time for the replication transfer (used in * order to detect timeouts during replication), and write what we * got from the socket to the dump file on disk. */ server.repl_transfer_lastio = server.unixtime; if ((nwritten = write(server.repl_transfer_fd,buf,nread)) != nread) { serverLog(LL_WARNING, "Write error or short write writing to the DB dump file " "needed for MASTER <-> REPLICA synchronization: %s", (nwritten == -1) ? strerror(errno) : "short write"); goto error; } server.repl_transfer_read += nread;
/* Delete the last 40 bytes from the file if we reached EOF. */ if (usemark && eof_reached) { if (ftruncate(server.repl_transfer_fd, server.repl_transfer_read - CONFIG_RUN_ID_SIZE) == -1) { serverLog(LL_WARNING, "Error truncating the RDB file received from the master " "for SYNC: %s", strerror(errno)); goto error; } }
/* Sync data on disk from time to time, otherwise at the end of the * transfer we may suffer a big delay as the memory buffers are copied * into the actual disk. */ if (server.repl_transfer_read >= server.repl_transfer_last_fsync_off + REPL_MAX_WRITTEN_BEFORE_FSYNC) { off_t sync_size = server.repl_transfer_read - server.repl_transfer_last_fsync_off; rdb_fsync_range(server.repl_transfer_fd, server.repl_transfer_last_fsync_off, sync_size); server.repl_transfer_last_fsync_off += sync_size; }
/* Check if the transfer is now complete */ if (!usemark) { if (server.repl_transfer_read == server.repl_transfer_size) eof_reached = 1; }
/* If the transfer is yet not complete, we need to read more, so * return ASAP and wait for the handler to be called again. */ if (!eof_reached) return; }
/* We reach this point in one of the following cases: * * 1. The replica is using diskless replication, that is, it reads data * directly from the socket to the Redis memory, without using * a temporary RDB file on disk. In that case we just block and * read everything from the socket. * * 2. Or when we are done reading from the socket to the RDB file, in * such case we want just to read the RDB file in memory. */ serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Flushing old data");
/* We need to stop any AOF rewriting child before flusing and parsing * the RDB, otherwise we'll create a copy-on-write disaster. */ if (server.aof_state != AOF_OFF) stopAppendOnly();
/* When diskless RDB loading is used by replicas, it may be configured * in order to save the current DB instead of throwing it away, * so that we can restore it in case of failed transfer. */
/* Ensure background save doesn't overwrite synced data */ if (server.child_type == CHILD_TYPE_RDB) { serverLog(LL_NOTICE, "Replica is about to load the RDB file received from the " "master, but there is a pending RDB child running. " "Killing process %ld and removing its temp file to avoid " "any race", (long) server.child_pid); killRDBChild(); }
/* Make sure the new file (also used for persistence) is fully synced * (not covered by earlier calls to rdb_fsync_range). */ if (fsync(server.repl_transfer_fd) == -1) { serverLog(LL_WARNING, "Failed trying to sync the temp DB to disk in " "MASTER <-> REPLICA synchronization: %s", strerror(errno)); cancelReplicationHandshake(1); return; }
/* Rename rdb like renaming rewrite aof asynchronously. */ int old_rdb_fd = open(server.rdb_filename,O_RDONLY|O_NONBLOCK); if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) { serverLog(LL_WARNING, "Failed trying to rename the temp DB into %s in " "MASTER <-> REPLICA synchronization: %s", server.rdb_filename, strerror(errno)); cancelReplicationHandshake(1); if (old_rdb_fd != -1) close(old_rdb_fd); return; } /* Close old rdb asynchronously. */ if (old_rdb_fd != -1) bioCreateCloseJob(old_rdb_fd);
if (rdbLoad(server.rdb_filename,&rsi,RDBFLAGS_REPLICATION) != C_OK) { serverLog(LL_WARNING, "Failed trying to load the MASTER synchronization " "DB from disk"); cancelReplicationHandshake(1); if (server.rdb_del_sync_files && allPersistenceDisabled()) { serverLog(LL_NOTICE,"Removing the RDB file obtained from " "the master. This replica has persistence " "disabled"); bg_unlink(server.rdb_filename); } /* Note that there's no point in restarting the AOF on sync failure, it'll be restarted when sync succeeds or replica promoted. */ return; }
/* Cleanup. */ if (server.rdb_del_sync_files && allPersistenceDisabled()) { serverLog(LL_NOTICE,"Removing the RDB file obtained from " "the master. This replica has persistence " "disabled"); bg_unlink(server.rdb_filename); }
if (use_diskless_load && server.repl_diskless_load == REPL_DISKLESS_LOAD_SWAPDB) { /* Create a backup of server.db[] and initialize to empty * dictionaries. */ diskless_load_backup = disklessLoadMakeBackup(); } /* We call to emptyDb even in case of REPL_DISKLESS_LOAD_SWAPDB * (Where disklessLoadMakeBackup left server.db empty) because we * want to execute all the auxiliary logic of emptyDb (Namely, * fire module events) */ emptyDb(-1,empty_db_flags,replicationEmptyDbCallback);
/* Before loading the DB into memory we need to delete the readable * handler, otherwise it will get called recursively since * rdbLoad() will call the event loop to process events from time to * time for non blocking loading. */ connSetReadHandler(conn, NULL); serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Loading DB in memory"); rdbSaveInfo rsi = RDB_SAVE_INFO_INIT; if (use_diskless_load) { rio rdb; rioInitWithConn(&rdb,conn,server.repl_transfer_size);
/* Put the socket in blocking mode to simplify RDB transfer. * We'll restore it when the RDB is received. */ connBlock(conn); connRecvTimeout(conn, server.repl_timeout*1000); startLoading(server.repl_transfer_size, RDBFLAGS_REPLICATION);
if (rdbLoadRio(&rdb,RDBFLAGS_REPLICATION,&rsi) != C_OK) { /* RDB loading failed. */ stopLoading(0); serverLog(LL_WARNING, "Failed trying to load the MASTER synchronization DB " "from socket"); cancelReplicationHandshake(1); rioFreeConn(&rdb, NULL);
/* Remove the half-loaded data in case we started with * an empty replica. */ emptyDb(-1,empty_db_flags,replicationEmptyDbCallback);
if (server.repl_diskless_load == REPL_DISKLESS_LOAD_SWAPDB) { /* Restore the backed up databases. */ disklessLoadRestoreBackup(diskless_load_backup); }
/* Note that there's no point in restarting the AOF on SYNC * failure, it'll be restarted when sync succeeds or the replica * gets promoted. */ return; }
/* RDB loading succeeded if we reach this point. */ if (server.repl_diskless_load == REPL_DISKLESS_LOAD_SWAPDB) { /* Delete the backup databases we created before starting to load * the new RDB. Now the RDB was loaded with success so the old * data is useless. */ disklessLoadDiscardBackup(diskless_load_backup, empty_db_flags); }
/* Verify the end mark is correct. */ if (usemark) { if (!rioRead(&rdb,buf,CONFIG_RUN_ID_SIZE) || memcmp(buf,eofmark,CONFIG_RUN_ID_SIZE) != 0) { stopLoading(0); serverLog(LL_WARNING,"Replication stream EOF marker is broken"); cancelReplicationHandshake(1); rioFreeConn(&rdb, NULL); return; } }
stopLoading(1);
/* Cleanup and restore the socket to the original state to continue * with the normal replication. */ rioFreeConn(&rdb, NULL); connNonBlock(conn); connRecvTimeout(conn,0);
voidreplicationCron(void) { /* Non blocking connection timeout? */ if (server.masterhost && (server.repl_state == REPL_STATE_CONNECTING || slaveIsInHandshakeState()) && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { serverLog(LL_WARNING,"Timeout connecting to the MASTER..."); cancelReplicationHandshake(1); }
/* Bulk transfer I/O timeout? */ if (server.masterhost && server.repl_state == REPL_STATE_TRANSFER && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { serverLog(LL_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value."); cancelReplicationHandshake(1); }
/* Timed out master when we are an already connected slave? */ if (server.masterhost && server.repl_state == REPL_STATE_CONNECTED && (time(NULL)-server.master->lastinteraction) > server.repl_timeout) { serverLog(LL_WARNING,"MASTER timeout: no data nor PING received..."); freeClient(server.master); }
/* Check if we should connect to a MASTER */ if (server.repl_state == REPL_STATE_CONNECT) { serverLog(LL_NOTICE,"Connecting to MASTER %s:%d", server.masterhost, server.masterport); connectWithMaster(); }
/* Send ACK to master from time to time. * Note that we do not send periodic acks to masters that don't * support PSYNC and replication offsets. */ if (server.masterhost && server.master && !(server.master->flags & CLIENT_PRE_PSYNC)) replicationSendAck(); }
voidsyncCommand(client *c) { .... /* Try a partial resynchronization if this is a PSYNC command. * If it fails, we continue with usual full resynchronization, however * when this happens masterTryPartialResynchronization() already * replied with: * * +FULLRESYNC <replid> <offset> * * So the slave knows the new replid and offset to try a PSYNC later * if the connection with the master is lost. */ if (!strcasecmp(c->argv[0]->ptr,"psync")) { if (masterTryPartialResynchronization(c) == C_OK) { server.stat_sync_partial_ok++; return; /* No full resync needed, return. */ } } else { /* If a slave uses SYNC, we are dealing with an old implementation * of the replication protocol (like redis-cli --slave). Flag the client * so that we don't expect to receive REPLCONF ACK feedbacks. */ c->flags |= CLIENT_PRE_PSYNC; }
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START; if (server.repl_disable_tcp_nodelay) connDisableTcpNoDelay(c->conn); /* Non critical if it fails. */ c->repldbfd = -1; c->flags |= CLIENT_SLAVE; listAddNodeTail(server.slaves,c);
/* Create the replication backlog if needed. */ if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) { /* When we create the backlog from scratch, we always use a new * replication ID and clear the ID2, since there is no valid * past history. */ changeReplicationId(); clearReplicationId2(); createReplicationBacklog(); serverLog(LL_NOTICE,"Replication backlog created, my new " "replication IDs are '%s' and '%s'", server.replid, server.replid2); }
/* CASE 1: BGSAVE is in progress, with disk target. */ if (server.child_type == CHILD_TYPE_RDB && server.rdb_child_type == RDB_CHILD_TYPE_DISK) { /* Ok a background save is in progress. Let's check if it is a good * one for replication, i.e. if there is another slave that is * registering differences since the server forked to save. */ client *slave; listNode *ln; listIter li;
listRewind(server.slaves,&li); while((ln = listNext(&li))) { slave = ln->value; /* If the client needs a buffer of commands, we can't use * a replica without replication buffer. */ if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END && (!(slave->flags & CLIENT_REPL_RDBONLY) || (c->flags & CLIENT_REPL_RDBONLY))) break; } /* To attach this slave, we check that it has at least all the * capabilities of the slave that triggered the current BGSAVE. */ if (ln && ((c->slave_capa & slave->slave_capa) == slave->slave_capa)) { /* Perfect, the server is already registering differences for * another slave. Set the right state, and copy the buffer. * We don't copy buffer if clients don't want. */ if (!(c->flags & CLIENT_REPL_RDBONLY)) copyClientOutputBuffer(c,slave); replicationSetupSlaveForFullResync(c,slave->psync_initial_offset); serverLog(LL_NOTICE,"Waiting for end of BGSAVE for SYNC"); } else { /* No way, we need to wait for the next BGSAVE in order to * register differences. */ serverLog(LL_NOTICE,"Can't attach the replica to the current BGSAVE. Waiting for next BGSAVE for SYNC"); }
/* CASE 2: BGSAVE is in progress, with socket target. */ } elseif (server.child_type == CHILD_TYPE_RDB && server.rdb_child_type == RDB_CHILD_TYPE_SOCKET) { /* There is an RDB child process but it is writing directly to * children sockets. We need to wait for the next BGSAVE * in order to synchronize. */ serverLog(LL_NOTICE,"Current BGSAVE has socket target. Waiting for next BGSAVE for SYNC");
/* CASE 3: There is no BGSAVE is progress. */ } else { if (server.repl_diskless_sync && (c->slave_capa & SLAVE_CAPA_EOF) && server.repl_diskless_sync_delay) { /* Diskless replication RDB child is created inside * replicationCron() since we want to delay its start a * few seconds to wait for more slaves to arrive. */ serverLog(LL_NOTICE,"Delay next BGSAVE for diskless SYNC"); } else { /* We don't have a BGSAVE in progress, let's start one. Diskless * or disk-based mode is determined by replica's capacity. */ if (!hasActiveChildProcess()) { startBgsaveForReplication(c->slave_capa); } else { serverLog(LL_NOTICE, "No BGSAVE in progress, but another BG operation is active. " "BGSAVE for replication delayed"); } } }
intstartBgsaveForReplication(int mincapa) { int retval; int socket_target = server.repl_diskless_sync && (mincapa & SLAVE_CAPA_EOF); listIter li; listNode *ln;
serverLog(LL_NOTICE,"Starting BGSAVE for SYNC with target: %s", socket_target ? "replicas sockets" : "disk");
rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); /* Only do rdbSave* when rsiptr is not NULL, * otherwise slave will miss repl-stream-db. */ if (rsiptr) { if (socket_target) retval = rdbSaveToSlavesSockets(rsiptr); else retval = rdbSaveBackground(server.rdb_filename,rsiptr); } else { serverLog(LL_WARNING,"BGSAVE for replication: replication information not available, can't generate the RDB file right now. Try later."); retval = C_ERR; }
/* If the target is socket, rdbSaveToSlavesSockets() already setup * the slaves for a full resync. Otherwise for disk target do it now.*/ if (!socket_target) { listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value;
/* Spawn an RDB child that writes the RDB to the sockets of the slaves * that are currently in SLAVE_STATE_WAIT_BGSAVE_START state. */ intrdbSaveToSlavesSockets(rdbSaveInfo *rsi) { listNode *ln; listIter li; pid_t childpid; int pipefds[2], rdb_pipe_write, safe_to_exit_pipe;
server.rdb_pipe_read = pipefds[0]; /* read end */ rdb_pipe_write = pipefds[1]; /* write end */ anetNonBlock(NULL, server.rdb_pipe_read);
safe_to_exit_pipe = pipefds[0]; /* read end */ server.rdb_child_exit_pipe = pipefds[1]; /* write end */
/* Collect the connections of the replicas we want to transfer * the RDB to, which are i WAIT_BGSAVE_START state. */ server.rdb_pipe_conns = zmalloc(sizeof(connection *)*listLength(server.slaves)); server.rdb_pipe_numconns = 0; server.rdb_pipe_numconns_writing = 0; listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value; if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) { server.rdb_pipe_conns[server.rdb_pipe_numconns++] = slave->conn; replicationSetupSlaveForFullResync(slave,getPsyncInitialOffset()); } }
/* Create the child process. */ if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) { /* Child */ int retval, dummy; rio rdb;
if (retval == C_OK) { sendChildCowInfo(CHILD_INFO_TYPE_RDB_COW_SIZE, "RDB"); }
rioFreeFd(&rdb); /* wake up the reader, tell it we're done. */ close(rdb_pipe_write); close(server.rdb_child_exit_pipe); /* close write end so that we can detect the close on the parent. */ /* hold exit until the parent tells us it's safe. we're not expecting * to read anything, just get the error when the pipe is closed. */ dummy = read(safe_to_exit_pipe, pipefds, 1); UNUSED(dummy); exitFromChild((retval == C_OK) ? 0 : 1);
} else { /* Parent */ close(safe_to_exit_pipe); if (childpid == -1) { serverLog(LL_WARNING,"Can't save in background: fork: %s", strerror(errno));
/* Undo the state change. The caller will perform cleanup on * all the slaves in BGSAVE_START state, but an early call to * replicationSetupSlaveForFullResync() turned it into BGSAVE_END */ listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value; if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END) { slave->replstate = SLAVE_STATE_WAIT_BGSAVE_START; } } close(rdb_pipe_write); close(server.rdb_pipe_read); zfree(server.rdb_pipe_conns); server.rdb_pipe_conns = NULL; server.rdb_pipe_numconns = 0; server.rdb_pipe_numconns_writing = 0; } else { serverLog(LL_NOTICE,"Background RDB transfer started by pid %ld", (long) childpid); server.rdb_save_time_start = time(NULL); server.rdb_child_type = RDB_CHILD_TYPE_SOCKET; close(rdb_pipe_write); /* close write in parent so that it can detect the close on the child. */ if (aeCreateFileEvent(server.el, server.rdb_pipe_read, AE_READABLE, rdbPipeReadHandler,NULL) == AE_ERR) { serverPanic("Unrecoverable error creating server.rdb_pipe_read file event."); } } return (childpid == -1) ? C_ERR : C_OK; } return C_OK; /* Unreached. */ }
/* Initialize the data structures needed for threaded I/O. */ voidinitThreadedIO(void) { server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread: * we'll handle I/O directly from the main thread. */ if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) { serverLog(LL_WARNING,"Fatal: too many I/O threads configured. " "The maximum number is %d.", IO_THREADS_MAX_NUM); exit(1); }
/* Spawn and initialize the I/O threads. */ for (int i = 0; i < server.io_threads_num; i++) { /* Things we do for all the threads including the main thread. */ io_threads_list[i] = listCreate(); if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */ pthread_t tid; pthread_mutex_init(&io_threads_mutex[i],NULL); setIOPendingCount(i, 0); pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */ if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize IO thread."); exit(1); } io_threads[i] = tid; } }
staticinlinevoidsetIOPendingCount(int i, unsignedlong count) { atomicSetWithSync(io_threads_pending[i], count); }
void *IOThreadMain(void *myid) { /* The ID is the thread number (from 0 to server.iothreads_num-1), and is * used by the thread to just manipulate a single sub-array of clients. */ long id = (unsignedlong)myid; char thdname[16];
while(1) { /* Wait for start */ for (int j = 0; j < 1000000; j++) { if (getIOPendingCount(id) != 0) break; }
/* Give the main thread a chance to stop this thread. */ if (getIOPendingCount(id) == 0) { pthread_mutex_lock(&io_threads_mutex[id]); pthread_mutex_unlock(&io_threads_mutex[id]); continue; }
serverAssert(getIOPendingCount(id) != 0);
/* Process: note that the main thread will never touch our list * before we drop the pending count to 0. */ listIter li; listNode *ln; listRewind(io_threads_list[id],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); if (io_threads_op == IO_THREADS_OP_WRITE) { writeToClient(c,0); } elseif (io_threads_op == IO_THREADS_OP_READ) { readQueryFromClient(c->conn); } else { serverPanic("io_threads_op value is unknown"); } } listEmpty(io_threads_list[id]); setIOPendingCount(id, 0); } }
inthandleClientsWithPendingReadsUsingThreads(void) { if (!server.io_threads_active || !server.io_threads_do_reads) return0; int processed = listLength(server.clients_pending_read); if (processed == 0) return0;
/* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; }
/* Give the start condition to the waiting threads, by setting the * start condition atomic var. */ io_threads_op = IO_THREADS_OP_READ; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); }
/* Also use the main thread to process a slice of clients. */ listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); readQueryFromClient(c->conn); } listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */ while(1) { unsignedlong pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; }
/* Run the list of clients again to process the new buffers. */ while(listLength(server.clients_pending_read)) { ln = listFirst(server.clients_pending_read); client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_READ; listDelNode(server.clients_pending_read,ln);
if (processPendingCommandsAndResetClient(c) == C_ERR) { /* If the client is no longer valid, we avoid * processing the client later. So we just go * to the next. */ continue; }
processInputBuffer(c);
/* We may have pending replies if a thread readQueryFromClient() produced * replies and did not install a write handler (it can't). */ if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c)) clientInstallWriteHandler(c); }
/* Update processed count on server */ server.stat_io_reads_processed += processed;
return processed; }
handleClientsWithPendingWritesUsingThreads
写操作,检查一下 I/O线程 是否开启,当任务量少的时候,会通过 lock(mutex) 临时阻塞子线程,因为子线程是一个死循环,就算没有任务也会占满 CPU 。如果没有写完,则会设置写回调,注册到 epoll 中,下次由主线程去写。
intstopThreadedIOIfNeeded(void) { int pending = listLength(server.clients_pending_write);
/* Return ASAP if IO threads are disabled (single threaded mode). */ if (server.io_threads_num == 1) return1;
if (pending < (server.io_threads_num*2)) { if (server.io_threads_active) stopThreadedIO(); return1; } else { return0; } }
inthandleClientsWithPendingWritesUsingThreads(void) { int processed = listLength(server.clients_pending_write); if (processed == 0) return0; /* Return ASAP if there are no clients. */
/* If I/O threads are disabled or we have few clients to serve, don't * use I/O threads, but the boring synchronous code. */ if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) { return handleClientsWithPendingWrites(); }
/* Start threads if needed. */ if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_write,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since * they are going to be closed ASAP. */ if (c->flags & CLIENT_CLOSE_ASAP) { listDelNode(server.clients_pending_write, ln); continue; }
int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; }
/* Give the start condition to the waiting threads, by setting the * start condition atomic var. */ io_threads_op = IO_THREADS_OP_WRITE; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); }
/* Also use the main thread to process a slice of clients. */ listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); writeToClient(c,0); } listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */ while(1) { unsignedlong pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; }
/* Run the list of clients again to install the write handler where * needed. */ listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln);
/* Install the write handler if there are pending writes in some * of the clients. */ if (clientHasPendingReplies(c) && connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) { freeClientAsync(c); } } listEmpty(server.clients_pending_write);
/* Update processed count on server */ server.stat_io_writes_processed += processed;
voidbioInit(void) { pthread_attr_t attr; pthread_t thread; size_t stacksize; int j;
/* Initialization of state vars and objects */ for (j = 0; j < BIO_NUM_OPS; j++) { pthread_mutex_init(&bio_mutex[j],NULL); pthread_cond_init(&bio_newjob_cond[j],NULL); pthread_cond_init(&bio_step_cond[j],NULL); bio_jobs[j] = listCreate(); bio_pending[j] = 0; }
/* Set the stack size as by default it may be small in some system */ pthread_attr_init(&attr); pthread_attr_getstacksize(&attr,&stacksize); if (!stacksize) stacksize = 1; /* The world is full of Solaris Fixes */ while (stacksize < REDIS_THREAD_STACK_SIZE) stacksize *= 2; pthread_attr_setstacksize(&attr, stacksize);
/* Ready to spawn our threads. We use the single argument the thread * function accepts in order to pass the job ID the thread is * responsible of. */ for (j = 0; j < BIO_NUM_OPS; j++) { void *arg = (void*)(unsignedlong) j; if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs."); exit(1); } bio_threads[j] = thread; } }
structbio_job { time_t time; /* Time at which the job was created. */ /* Job specific arguments.*/ int fd; /* Fd for file based background jobs */ lazy_free_fn *free_fn; /* Function that will free the provided arguments */ void *free_args[]; /* List of arguments to be passed to the free function */ };
/* Check that the type is within the right interval. */ if (type >= BIO_NUM_OPS) { serverLog(LL_WARNING, "Warning: bio thread started with wrong type %lu",type); returnNULL; }
switch (type) { case BIO_CLOSE_FILE: redis_set_thread_title("bio_close_file"); break; case BIO_AOF_FSYNC: redis_set_thread_title("bio_aof_fsync"); break; case BIO_LAZY_FREE: redis_set_thread_title("bio_lazy_free"); break; }
redisSetCpuAffinity(server.bio_cpulist);
makeThreadKillable();
pthread_mutex_lock(&bio_mutex[type]); /* Block SIGALRM so we are sure that only the main thread will * receive the watchdog signal. */ sigemptyset(&sigset); sigaddset(&sigset, SIGALRM); if (pthread_sigmask(SIG_BLOCK, &sigset, NULL)) serverLog(LL_WARNING, "Warning: can't mask SIGALRM in bio.c thread: %s", strerror(errno));
while(1) { listNode *ln;
/* The loop always starts with the lock hold. */ if (listLength(bio_jobs[type]) == 0) { pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]); continue; } /* Pop the job from the queue. */ ln = listFirst(bio_jobs[type]); job = ln->value; /* It is now possible to unlock the background system as we know have * a stand alone job structure to process.*/ pthread_mutex_unlock(&bio_mutex[type]);
/* Process the job accordingly to its type. */ if (type == BIO_CLOSE_FILE) { close(job->fd); } elseif (type == BIO_AOF_FSYNC) { redis_fsync(job->fd); } elseif (type == BIO_LAZY_FREE) { job->free_fn(job->free_args); } else { serverPanic("Wrong job type in bioProcessBackgroundJobs()."); } zfree(job);
/* Lock again before reiterating the loop, if there are no longer * jobs to process we'll block again in pthread_cond_wait(). */ pthread_mutex_lock(&bio_mutex[type]); listDelNode(bio_jobs[type],ln); bio_pending[type]--;
/* Unblock threads blocked on bioWaitStepOfType() if any. */ pthread_cond_broadcast(&bio_step_cond[type]); } }
关闭文件描述符
关闭文件描述符,有可能会删除掉文件,引起阻塞。因为 Redis 实现的时候会通过 rename 覆盖掉原有文件,将文件描述符的关闭交给 bio 子线程避免阻塞。
voidpropagate(struct redisCommand *cmd, int dbid, robj **argv, int argc, int flags) { if (!server.replication_allowed) return;
/* Propagate a MULTI request once we encounter the first command which * is a write command. * This way we'll deliver the MULTI/..../EXEC block as a whole and * both the AOF and the replication link will have the same consistency * and atomicity guarantees. */ if (server.in_exec && !server.propagate_in_transaction) execCommandPropagateMulti(dbid);
/* This needs to be unreachable since the dataset should be fixed during * client pause, otherwise data may be lossed during a failover. */ serverAssert(!(areClientsPaused() && !server.client_pause_in_transaction));
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF) feedAppendOnlyFile(cmd,dbid,argv,argc); if (flags & PROPAGATE_REPL) replicationFeedSlaves(server.slaves,dbid,argv,argc); }
voidfeedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) { sds buf = sdsempty(); /* The DB this command was targeting is not the same as the last command * we appended. To issue a SELECT command is needed. */ if (dictid != server.aof_selected_db) { char seldb[64];
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand || cmd->proc == expireatCommand) { /* Translate EXPIRE/PEXPIRE/EXPIREAT into PEXPIREAT */ buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]); } elseif (cmd->proc == setCommand && argc > 3) { robj *pxarg = NULL; /* When SET is used with EX/PX argument setGenericCommand propagates them with PX millisecond argument. * So since the command arguments are re-written there, we can rely here on the index of PX being 3. */ if (!strcasecmp(argv[3]->ptr, "px")) { pxarg = argv[4]; } /* For AOF we convert SET key value relative time in milliseconds to SET key value absolute time in * millisecond. Whenever the condition is true it implies that original SET has been transformed * to SET PX with millisecond time argument so we do not need to worry about unit here.*/ if (pxarg) { robj *millisecond = getDecodedObject(pxarg); longlong when = strtoll(millisecond->ptr,NULL,10); when += mstime();
decrRefCount(millisecond);
robj *newargs[5]; newargs[0] = argv[0]; newargs[1] = argv[1]; newargs[2] = argv[2]; newargs[3] = shared.pxat; newargs[4] = createStringObjectFromLongLong(when); buf = catAppendOnlyGenericCommand(buf,5,newargs); decrRefCount(newargs[4]); } else { buf = catAppendOnlyGenericCommand(buf,argc,argv); } } else { /* All the other commands don't need translation or need the * same translation already operated in the command vector * for the replication itself. */ buf = catAppendOnlyGenericCommand(buf,argc,argv); }
/* Append to the AOF buffer. This will be flushed on disk just before * of re-entering the event loop, so before the client will get a * positive reply about the operation performed. */ if (server.aof_state == AOF_ON) server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
/* If a background append only file rewriting is in progress we want to * accumulate the differences between the child DB and the current one * in a buffer, so that when the child process will do its work we * can append the differences to the new append only file. */ if (server.child_type == CHILD_TYPE_AOF) aofRewriteBufferAppend((unsignedchar*)buf,sdslen(buf));
sdsfree(buf); }
flushAppendOnlyFile
AOF日志同步到硬盘的策略有三种,第一种不同步,由内核自己决定Flush时机,另一种每次都同步,但是 fsync 是会阻塞的,因此还有第三种每秒同步,通过 BIO 子线程,每秒去同步 fsync 一次,其实说是 fsync 也不准确,在 Linux 下用的是 fdatasync 省去了写文件的元数据开销。
if (hasActiveChildProcess()) return C_ERR; if (aofCreatePipes() != C_OK) return C_ERR; if ((childpid = redisFork(CHILD_TYPE_AOF)) == 0) { char tmpfile[256];
/* Child */ redisSetProcTitle("redis-aof-rewrite"); redisSetCpuAffinity(server.aof_rewrite_cpulist); snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid()); if (rewriteAppendOnlyFile(tmpfile) == C_OK) { sendChildCowInfo(CHILD_INFO_TYPE_AOF_COW_SIZE, "AOF rewrite"); exitFromChild(0); } else { exitFromChild(1); } } else { /* Parent */ if (childpid == -1) { serverLog(LL_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno)); aofClosePipes(); return C_ERR; } serverLog(LL_NOTICE, "Background append only file rewriting started by pid %ld",(long) childpid); server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL);
/* We set appendseldb to -1 in order to force the next call to the * feedAppendOnlyFile() to issue a SELECT command, so the differences * accumulated by the parent into server.aof_rewrite_buf will start * with a SELECT statement and it will be safe to merge. */ server.aof_selected_db = -1; replicationScriptCacheFlush(); return C_OK; } return C_OK; /* unreached */ }
voidcheckChildrenDone(void) { int statloc; pid_t pid;
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) { int exitcode = WEXITSTATUS(statloc); int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
/* sigKillChildHandler catches the signal and calls exit(), but we * must make sure not to flag lastbgsave_status, etc incorrectly. * We could directly terminate the child process via SIGUSR1 * without handling it, but in this case Valgrind will log an * annoying error. */ if (exitcode == SERVER_CHILD_NOERROR_RETVAL) { bysignal = SIGUSR1; exitcode = 1; }
if (pid == -1) { serverLog(LL_WARNING,"wait3() returned an error: %s. " "child_type: %s, child_pid = %d", strerror(errno), strChildType(server.child_type), (int) server.child_pid); } elseif (pid == server.child_pid) { if (server.child_type == CHILD_TYPE_RDB) { backgroundSaveDoneHandler(exitcode, bysignal); } elseif (server.child_type == CHILD_TYPE_AOF) { backgroundRewriteDoneHandler(exitcode, bysignal); } elseif (server.child_type == CHILD_TYPE_MODULE) { ModuleForkDoneHandler(exitcode, bysignal); } else { serverPanic("Unknown child type %d for child pid %d", server.child_type, server.child_pid); exit(1); } if (!bysignal && exitcode == 0) receiveChildInfo(); resetChildState(); } else { if (!ldbRemoveChild(pid)) { serverLog(LL_WARNING, "Warning, detected child with unmatched pid: %ld", (long) pid); } }
/* start any pending forks immediately. */ replicationStartPendingFork(); } }
/* If there is not a background saving/rewrite in progress check if * we have to save/rewrite now. */ for (j = 0; j < server.saveparamslen; j++) { structsaveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes, * the given amount of seconds, and if the latest bgsave was * successful or if, in case of an error, at least * CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */ if (server.dirty >= sp->changes && server.unixtime-server.lastsave > sp->seconds && (server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) { serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds); rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); rdbSaveBackground(server.rdb_filename,rsiptr); break; } }
如何保证领导者的日志一定是最新的呢?前面也提到了 日志由 Term 任期, index 日志索引,日志内容所构成,每次复制都会去检查前一个日志的任期和索引是否相同,如果相同,我们则可以断定前面的日志也一定是相同的。
其次如果领导者复制给了跟随者日志,但是随后就宕机了,这个时候没有应用于状态机,怎么办?这个时候就依赖于 Term 任期字段,新的领导者首先通过上面的机制保证了它的日志一定是最全的,同时它的任期一定是更高的,于是就可以将其任期之前的未提交的直接提交了,然后同步给其他节点。再加上 Raft 整个系统实现是幂等性的,即使因为超时或者种种原因重新执行指令也不会发生任何副作用。
type RaftState uint32 const ( // Follower is the initial state of a Raft node. Follower RaftState = iota // Candidate is one of the valid states of a Raft node. Candidate // Leader is one of the valid states of a Raft node. Leader // Shutdown is the terminal state of a Raft node. Shutdown // 关闭状态 )
// Cache the latest log from LogStore lastLogIndex uint64// 最后一条索引 lastLogTerm uint64// 最后一条日志任期
// The current state state RaftState // 节点状态,前面的三态 }
附加日志 RPC 请求,这里可以对照着论文看了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
type AppendEntriesRequest struct { RPCHeader // 协议版本
// Provide the current term and leader Term uint64// 任期 Leader []byte// 领导者信息
// Provide the previous entries for integrity checking PrevLogEntry uint64// 前一个日志的索引 PrevLogTerm uint64// 前一个日志的任期
// New entries to commit Entries []*Log // 新的日志
// Commit index on the leader LeaderCommitIndex uint64// 已提交的最大编号,心跳带出,让跟随者也附加 }
附加日志 RPC 响应。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
type AppendEntriesResponse struct { RPCHeader
// Newer term if leader is out of date Term uint64// 当前任期
// Last Log is a hint to help accelerate rebuilding slow nodes LastLog uint64// 最后一条日志索引 用于快速找到缺失的日志(论文里没有)
// We may not succeed if we have a conflicting entry Success bool// 是否成功 如果不匹配就不成功
// There are scenarios where this request didn't succeed // but there's no need to wait/back-off the next attempt. NoRetryBackoff bool// 是否不等待直接重试,论文没有 属于扩充项 加速用 }
投票 RPC 请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
type RequestVoteRequest struct { RPCHeader
// Provide the term and our id Term uint64// 任期 Candidate []byte// 候选人信息
// Used to ensure safety LastLogIndex uint64// 最后一条日志索引 LastLogTerm uint64// 最后一条日志任期
// Used to indicate to peers if this vote was triggered by a leadership // transfer. It is required for leadership transfer to work, because servers // wouldn't vote otherwise if they are aware of an existing leader. LeadershipTransfer bool// hashicorp 实现的一种主动转移领导的快速项,论文没有 }
投票 RPC 响应。
1 2 3 4 5 6 7 8 9
type RequestVoteResponse struct { RPCHeader
// Newer term if leader is out of date. Term uint64// 任期
// Is the vote granted. Granted bool// 投我吗 }
安装快照 RPC 请求。
快照主要是当 日志项太多的时候,将其合并成一个快照复制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
type InstallSnapshotRequest struct { RPCHeader SnapshotVersion SnapshotVersion // 快照版本 扩展
Term uint64// 任期 Leader []byte// 领导信息
// These are the last index/term included in the snapshot LastLogIndex uint64// 快照中最后一条日志索引 LastLogTerm uint64// 快照中最后一条日志任期
// Cluster membership. Configuration []byte// 配置 // Log index where 'Configuration' entry was originally written. ConfigurationIndex uint64// 配置项索引
funcNewRaft(conf *Config, fsm FSM, logs LogStore, stable StableStore, snaps SnapshotStore, trans Transport) (*Raft, error) { .... // Initialize as a follower. r.setState(Follower)
// Start as leader if specified. This should only be used // for testing purposes. if conf.StartAsLeader { r.setState(Leader) r.setLeader(r.localAddr) } .... // Start the background work. r.goFunc(r.run) r.goFunc(r.runFSM) r.goFunc(r.runSnapshots) return r, nil }
func(r *Raft) run() { for { // Check if we are doing a shutdown select { case <-r.shutdownCh: // Clear the leader to prevent forwarding r.setLeader("") return default: }
// Enter into a sub-FSM switch r.getState() { case Follower: r.runFollower() case Candidate: r.runCandidate() case Leader: r.runLeader() } } }
func(r *Raft) runCandidate() { // Start vote for us, and set a timeout voteCh := r.electSelf() .... electionTimer := randomTimeout(r.conf.ElectionTimeout)
// Tally the votes, need a simple majority grantedVotes := 0 votesNeeded := r.quorumSize() r.logger.Debug(fmt.Sprintf("Votes needed: %d", votesNeeded))
for r.getState() == Candidate { select { case rpc := <-r.rpcCh: r.processRPC(rpc)
case vote := <-voteCh: // Check if the term is greater than ours, bail if vote.Term > r.getCurrentTerm() { r.logger.Debug("Newer term discovered, fallback to follower") r.setState(Follower) r.setCurrentTerm(vote.Term) return }
// Check if the vote is granted if vote.Granted { grantedVotes++ r.logger.Debug(fmt.Sprintf("Vote granted from %s in term %v. Tally: %d", vote.voterID, vote.Term, grantedVotes)) }
// Check if we've become the leader if grantedVotes >= votesNeeded { r.logger.Info(fmt.Sprintf("Election won. Tally: %d", grantedVotes)) r.setState(Leader) r.setLeader(r.localAddr) return }
case c := <-r.configurationChangeCh: // Reject any operations since we are not the leader c.respond(ErrNotLeader)
case a := <-r.applyCh: // Reject any operations since we are not the leader a.respond(ErrNotLeader)
case v := <-r.verifyCh: // Reject any operations since we are not the leader v.respond(ErrNotLeader)
case r := <-r.userRestoreCh: // Reject any restores since we are not the leader r.respond(ErrNotLeader)
case c := <-r.configurationsCh: c.configurations = r.configurations.Clone() c.respond(nil)
case b := <-r.bootstrapCh: b.respond(ErrCantBootstrap)
case <-electionTimer: // Election failed! Restart the election. We simply return, // which will kick us back into runCandidate r.logger.Warn("Election timeout reached, restarting election") return
func(r *Raft) runLeader() { .... // setup leader state. This is only supposed to be accessed within the // leaderloop. r.setupLeaderState() .... // Start a replication routine for each peer r.startStopReplication()
// Dispatch a no-op log entry first. This gets this leader up to the latest // possible commit index, even in the absence of client commands. This used // to append a configuration entry instead of a noop. However, that permits // an unbounded number of uncommitted configurations in the log. We now // maintain that there exists at most one uncommitted configuration entry in // any log, so we have to do proper no-ops here. noop := &logFuture{ log: Log{ Type: LogNoop, }, } r.dispatchLogs([]*logFuture{noop})
// Sit in the leader loop until we step down r.leaderLoop() }
switch msgType { case userMsg: if err := m.readUserMsg(bufConn, dec); err != nil { m.logger.Printf("[ERR] memberlist: Failed to receive user message: %s %s", err, LogConn(conn)) } case pushPullMsg: // Increment counter of pending push/pulls numConcurrent := atomic.AddUint32(&m.pushPullReq, 1) defer atomic.AddUint32(&m.pushPullReq, ^uint32(0))
// Check if we have too many open push/pull requests if numConcurrent >= maxPushPullRequests { m.logger.Printf("[ERR] memberlist: Too many pending push/pull requests") return }
func(m *Memberlist) handleCommand(buf []byte, from net.Addr, timestamp time.Time) { // Decode the message type msgType := messageType(buf[0]) buf = buf[1:]
// Switch on the msgType switch msgType { case compoundMsg: m.handleCompound(buf, from, timestamp) case compressMsg: m.handleCompressed(buf, from, timestamp)
case pingMsg: m.handlePing(buf, from) case indirectPingMsg: m.handleIndirectPing(buf, from) case ackRespMsg: m.handleAck(buf, from, timestamp) case nackRespMsg: m.handleNack(buf, from)
case suspectMsg: fallthrough case aliveMsg: fallthrough case deadMsg: fallthrough case userMsg: // Determine the message queue, prioritize alive queue := m.lowPriorityMsgQueue if msgType == aliveMsg { queue = m.highPriorityMsgQueue }
// Check for overflow and append if not full m.msgQueueLock.Lock() if queue.Len() >= m.config.HandoffQueueDepth { m.logger.Printf("[WARN] memberlist: handler queue full, dropping message (%d) %s", msgType, LogAddress(from)) } else { queue.PushBack(msgHandoff{msgType, buf, from}) } m.msgQueueLock.Unlock()
// Notify of pending message select { case m.handoffCh <- struct{}{}: default: }
default: m.logger.Printf("[ERR] memberlist: msg type (%d) not supported %s", msgType, LogAddress(from)) } }
// If we already have tickers, then don't do anything, since we're // scheduled iflen(m.tickers) > 0 { return }
// Create the stop tick channel, a blocking channel. We close this // when we should stop the tickers. stopCh := make(chanstruct{})
// Create a new probeTicker if m.config.ProbeInterval > 0 { t := time.NewTicker(m.config.ProbeInterval) go m.triggerFunc(m.config.ProbeInterval, t.C, stopCh, m.probe) m.tickers = append(m.tickers, t) }
// Create a push pull ticker if needed if m.config.PushPullInterval > 0 { go m.pushPullTrigger(stopCh) }
// Create a gossip ticker if needed if m.config.GossipInterval > 0 && m.config.GossipNodes > 0 { t := time.NewTicker(m.config.GossipInterval) go m.triggerFunc(m.config.GossipInterval, t.C, stopCh, m.gossip) m.tickers = append(m.tickers, t) }
// If we made any tickers, then record the stopTick channel for // later. iflen(m.tickers) > 0 { m.stopTick = stopCh } }
// We use our health awareness to scale the overall probe interval, so we // slow down if we detect problems. The ticker that calls us can handle // us running over the base interval, and will skip missed ticks. probeInterval := m.awareness.ScaleTimeout(m.config.ProbeInterval) if probeInterval > m.config.ProbeInterval { metrics.IncrCounter([]string{"memberlist", "degraded", "probe"}, 1) }
// Mark the sent time here, which should be after any pre-processing but // before system calls to do the actual send. This probably over-reports // a bit, but it's the best we can do. We had originally put this right // after the I/O, but that would sometimes give negative RTT measurements // which was not desirable. sent := time.Now()
// Send a ping to the node. If this node looks like it's suspect or dead, // also tack on a suspect message so that it has a chance to refute as // soon as possible. deadline := sent.Add(probeInterval) addr := node.Address()
// Arrange for our self-awareness to get updated. var awarenessDelta int deferfunc() { m.awareness.ApplyDelta(awarenessDelta) }() if node.State == StateAlive { if err := m.encodeAndSendMsg(node.FullAddress(), pingMsg, &ping); err != nil { m.logger.Printf("[ERR] memberlist: Failed to send ping: %s", err) if failedRemote(err) { goto HANDLE_REMOTE_FAILURE } else { return } } } else { var msgs [][]byte if buf, err := encode(pingMsg, &ping); err != nil { m.logger.Printf("[ERR] memberlist: Failed to encode ping message: %s", err) return } else { msgs = append(msgs, buf.Bytes()) } s := suspect{Incarnation: node.Incarnation, Node: node.Name, From: m.config.Name} if buf, err := encode(suspectMsg, &s); err != nil { m.logger.Printf("[ERR] memberlist: Failed to encode suspect message: %s", err) return } else { msgs = append(msgs, buf.Bytes()) }
compound := makeCompoundMessage(msgs) if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, compound.Bytes()); err != nil { m.logger.Printf("[ERR] memberlist: Failed to send compound ping and suspect message to %s: %s", addr, err) if failedRemote(err) { goto HANDLE_REMOTE_FAILURE } else { return } } }
// Arrange for our self-awareness to get updated. At this point we've // sent the ping, so any return statement means the probe succeeded // which will improve our health until we get to the failure scenarios // at the end of this function, which will alter this delta variable // accordingly. awarenessDelta = -1
// Wait for response or round-trip-time. select { case v := <-ackCh: if v.Complete == true { if m.config.Ping != nil { rtt := v.Timestamp.Sub(sent) m.config.Ping.NotifyPingComplete(&node.Node, rtt, v.Payload) } return }
// As an edge case, if we get a timeout, we need to re-enqueue it // here to break out of the select below. if v.Complete == false { ackCh <- v } case <-time.After(m.config.ProbeTimeout): // Note that we don't scale this timeout based on awareness and // the health score. That's because we don't really expect waiting // longer to help get UDP through. Since health does extend the // probe interval it will give the TCP fallback more time, which // is more active in dealing with lost packets, and it gives more // time to wait for indirect acks/nacks. m.logger.Printf("[DEBUG] memberlist: Failed ping: %s (timeout reached)", node.Name) }
HANDLE_REMOTE_FAILURE: // Get some random live nodes. m.nodeLock.RLock() kNodes := kRandomNodes(m.config.IndirectChecks, m.nodes, func(n *nodeState)bool { return n.Name == m.config.Name || n.Name == node.Name || n.State != StateAlive }) m.nodeLock.RUnlock()
// Attempt an indirect ping. expectedNacks := 0 selfAddr, selfPort = m.getAdvertise() ind := indirectPingReq{ SeqNo: ping.SeqNo, Target: node.Addr, Port: node.Port, Node: node.Name, SourceAddr: selfAddr, SourcePort: selfPort, SourceNode: m.config.Name, } for _, peer := range kNodes { // We only expect nack to be sent from peers who understand // version 4 of the protocol. if ind.Nack = peer.PMax >= 4; ind.Nack { expectedNacks++ }
// Also make an attempt to contact the node directly over TCP. This // helps prevent confused clients who get isolated from UDP traffic // but can still speak TCP (which also means they can possibly report // misinformation to other nodes via anti-entropy), avoiding flapping in // the cluster. // // This is a little unusual because we will attempt a TCP ping to any // member who understands version 3 of the protocol, regardless of // which protocol version we are speaking. That's why we've included a // config option to turn this off if desired. fallbackCh := make(chanbool, 1)
// Wait for the acks or timeout. Note that we don't check the fallback // channel here because we want to issue a warning below if that's the // *only* way we hear back from the peer, so we have to let this time // out first to allow the normal UDP-based acks to come in. select { case v := <-ackCh: if v.Complete == true { return } }
// Finally, poll the fallback channel. The timeouts are set such that // the channel will have something or be closed without having to wait // any additional time here. for didContact := range fallbackCh { if didContact { m.logger.Printf("[WARN] memberlist: Was able to connect to %s but other probes failed, network may be misconfigured", node.Name) return } }
// Update our self-awareness based on the results of this failed probe. // If we don't have peers who will send nacks then we penalize for any // failed probe as a simple health metric. If we do have peers to nack // verify, then we can use that as a more sophisticated measure of self- // health because we assume them to be working, and they can help us // decide if the probed node was really dead or if it was something wrong // with ourselves. awarenessDelta = 0 if expectedNacks > 0 { if nackCount := len(nackCh); nackCount < expectedNacks { awarenessDelta += (expectedNacks - nackCount) } } else { awarenessDelta += 1 }
// No acks received from target, suspect it as failed. m.logger.Printf("[INFO] memberlist: Suspect %s has failed, no acks received", node.Name) s := suspect{Incarnation: node.Incarnation, Node: node.Name, From: m.config.Name} m.suspectNode(&s) }
func(m *Memberlist) pushPull() { // Get a random live node m.nodeLock.RLock() nodes := kRandomNodes(1, m.nodes, func(n *nodeState)bool { return n.Name == m.config.Name || n.State != StateAlive }) m.nodeLock.RUnlock()
// If no nodes, bail iflen(nodes) == 0 { return } node := nodes[0]
// Attempt a push pull if err := m.pushPullNode(node.FullAddress(), false); err != nil { m.logger.Printf("[ERR] memberlist: Push/Pull with %s failed: %s", node.Name, err) } }
// pushPullNode does a complete state exchange with a specific node. func(m *Memberlist) pushPullNode(a Address, join bool) error { defer metrics.MeasureSince([]string{"memberlist", "pushPullNode"}, time.Now())
// Attempt to send and receive with the node remote, userState, err := m.sendAndReceiveState(a, join) if err != nil { return err }
// Get some random live, suspect, or recently dead nodes m.nodeLock.RLock() kNodes := kRandomNodes(m.config.GossipNodes, m.nodes, func(n *nodeState)bool { if n.Name == m.config.Name { returntrue }
switch n.State { case StateAlive, StateSuspect: returnfalse
case StateDead: return time.Since(n.StateChange) > m.config.GossipToTheDeadTime
default: returntrue } }) m.nodeLock.RUnlock()
// Compute the bytes available bytesAvail := m.config.UDPBufferSize - compoundHeaderOverhead if m.config.EncryptionEnabled() { bytesAvail -= encryptOverhead(m.encryptionVersion()) }
for _, node := range kNodes { // Get any pending broadcasts msgs := m.getBroadcasts(compoundOverhead, bytesAvail) iflen(msgs) == 0 { return }
addr := node.Address() iflen(msgs) == 1 { // Send single message as is if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, msgs[0]); err != nil { m.logger.Printf("[ERR] memberlist: Failed to send gossip to %s: %s", addr, err) } } else { // Otherwise create and send a compound message compound := makeCompoundMessage(msgs) if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, compound.Bytes()); err != nil { m.logger.Printf("[ERR] memberlist: Failed to send gossip to %s: %s", addr, err) } } } }
/* The corresponding word size */ #define SIZE_SZ (sizeof(INTERNAL_SIZE_T))
structmalloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ // ----------------------------------------------------------------------- structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
/* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */ #define PREV_INUSE 0x1 /* extract inuse bit of previous chunk */ #define prev_inuse(p) ((p)->size & PREV_INUSE) /* size field is or'ed with IS_MMAPPED if the chunk was obtained with mmap() */ #define IS_MMAPPED 0x2 /* check for mmap()'ed chunk */ #define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained from a non-main arena. This is only set immediately before handing the chunk to the user, if necessary. */ #define NON_MAIN_ARENA 0x4
/* check for chunk from non-main arena */ #define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA)
/* Memory map support */ int n_mmaps; int n_mmaps_max; int max_n_mmaps; /* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */ int no_dyn_threshold;
/* Statistics */ INTERNAL_SIZE_T mmapped_mem; /*INTERNAL_SIZE_T sbrked_mem;*/ /*INTERNAL_SIZE_T max_sbrked_mem;*/ INTERNAL_SIZE_T max_mmapped_mem; INTERNAL_SIZE_T max_total_mem; /* only kept for NO_THREADS */
/* First address handed out by MORECORE/sbrk. */ char* sbrk_base; };
若到这一步要么是 还没找到合适的内存,或者是 chunk_size 是一个 大的请求,则先遍历 fast bins,将相邻的 chunk 进行合并,放入到 unsorted bin 中,从 unstorted bin 中进行查找,一边找一边将其放入正确的 bins 中,同时在 binmap中进行标记。如果找到则返回给用户,若 unsorted bin 只有一个 chunk,且 该 chunk 为 last remainder chunk,且我们需要的是一个 small bin chunk,则将其切分,剩余部分依然不动,此步骤最多尝试 MAX_ITERS(10000)次,防止因为 unsored bin 的 chunk 过多而影响分配效率。
最后还是找不到,那就在 large bins 中按照最佳匹配的原则,从更大的 bins 中进行查找,查找方式是通过遍历 binmap,找一个合适的 chunk,并将其切分,成功则返回,否则下一步。
只好从 top chunk 进行切分了(回收的时候也是从 top chunk 进行切分,埋下了长周期的内存无法回收导致内存暴涨的伏笔),不成功下一步。
又开始打 fast bins 的注意了,主要是 fast bins 回收的时候没有加锁,而是采用 lock-free 方式(Compareand-Swap)回收,因此有可能里面已经有 chunk 了,这时候又开始合并,放入 unsorted bin,但是却是从 small bins 或从 large bins 中再去查找,这主要是因为,在第 5,6 步的时候,如果在 small bins 中找不到合适的 chunk,就合并 fast bins 到 unsorted bin,然后放回到指定的 small bins 和 large bins 中,但是并没有再去扫描一下相应的 bins,这里相当于再补上一刀。
a = get_free_list (); if (a == NULL) { /* Nothing immediately available, so generate a new arena. */ if (narenas_limit == 0) { if (mp_.arena_max != 0) narenas_limit = mp_.arena_max; elseif (narenas > mp_.arena_test) { int n = __get_nprocs ();
if (n >= 1) narenas_limit = NARENAS_FROM_NCORES (n); else /* We have no information about the system. Assume two cores. */ narenas_limit = NARENAS_FROM_NCORES (2); } } repeat:; size_t n = narenas; /* NB: the following depends on the fact that (size_t)0 - 1 is a very large number and that the underflow is OK. If arena_max is set the value of arena_test is irrelevant. If arena_test is set but narenas is not yet larger or equal to arena_test narenas_limit is 0. There is no possibility for narenas to be too big for the test to always fail since there is not enough address space to create that many arenas. */ if (__builtin_expect (n <= narenas_limit - 1, 0)) { if (catomic_compare_and_exchange_bool_acq (&narenas, n + 1, n)) goto repeat; a = _int_new_arena (size); if (__builtin_expect (a == NULL, 0)) catomic_decrement (&narenas); } else a = reused_arena (avoid_arena); } #else if(!a_tsd) a = a_tsd = &main_arena; else { a = a_tsd->next; if(!a) { /* This can only happen while initializing the new arena. */ (void)mutex_lock(&main_arena.mutex); THREAD_STAT(++(main_arena.stat_lock_wait)); return &main_arena; } }
/* Check the global, circularly linked list for available arenas. */ bool retried = false; repeat: do { if(!mutex_trylock(&a->mutex)) { if (retried) (void)mutex_unlock(&list_lock); THREAD_STAT(++(a->stat_lock_loop)); tsd_setspecific(arena_key, (void *)a); return a; } a = a->next; } while(a != a_tsd);
/* If not even the list_lock can be obtained, try again. This can happen during `atfork', or for example on systems where thread creation makes it temporarily impossible to obtain _any_ locks. */ if(!retried && mutex_trylock(&list_lock)) { /* We will block to not run in a busy loop. */ (void)mutex_lock(&list_lock);
/* Since we blocked there might be an arena available now. */ retried = true; a = a_tsd; goto repeat; }
/* Nothing immediately available, so generate a new arena. */ a = _int_new_arena(size); (void)mutex_unlock(&list_lock); #endif
staticvoid* _int_malloc(mstate av, size_t bytes) { INTERNAL_SIZE_T nb; /* normalized request size */ unsignedint idx; /* associated bin index */ mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */ INTERNAL_SIZE_T size; /* its size */ int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */ unsignedlong remainder_size; /* its size */
unsignedint block; /* bit map traverser */ unsignedint bit; /* bit map traverser */ unsignedintmap; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */ mchunkptr bck; /* misc temp for linking */
constchar *errstr = NULL;
/* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */
checked_request2size(bytes, nb);
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
else { idx = largebin_index(nb); if (have_fastchunks(av)) malloc_consolidate(av); }
/* Process recently freed or remaindered chunks, taking one only if it is exact fit, or, if this a small request, the chunk is remainder from the most recent non-exact fit. Place other traversed chunks in bins. Note that this step is the only place in any routine where chunks are placed in bins. The outer loop here is needed because we might not realize until near the end of malloc that we should have consolidated, so must do so and retry. This happens at most once, and only when we would otherwise need to expand memory to service a "small" request. */
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */
/* maintain large bins in sorted order */ if (fwd != bck) { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert((bck->bk->size & NON_MAIN_ARENA) == 0); if ((unsignedlong)(size) < (unsignedlong)(bck->bk->size)) { fwd = bck; bck = bck->bk;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last(bin) && victim->size == victim->fd->size) victim = victim->fd;
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; } /* Split */ else { remainder = chunk_at_offset(victim, nb); /* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0)) { errstr = "malloc(): corrupted unsorted chunks"; goto errout; } remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; if (!in_smallbin_range(remainder_size)) { remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); } check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } }
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected. The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */
++idx; bin = bin_at(av,idx); block = idx2block(idx); map = av->binmap[block]; bit = idx2bit(idx);
for (;;) {
/* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ( (map = av->binmap[block]) == 0);
bin = bin_at(av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0) { bin = next_bin(bin); bit <<= 1; assert(bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last(bin);
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin(bin); bit <<= 1; }
else { size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */ assert((unsignedlong)(size) >= (unsignedlong)(nb));
remainder_size = size - nb;
/* unlink */ unlink(victim, bck, fwd);
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; }
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations). We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */
第八步,从 top chunk 中进行切分,回收也是从 top chunk 从高往低释放回给内核,因此如果后分配的没有释放,会导致先分配的已释放都没办法还回给内核。
1 2 3 4 5 6 7 8 9 10
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks(av)) { malloc_consolidate(av); /* restore original bin index */ if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); }
staticvoid* sysmalloc(INTERNAL_SIZE_T nb, mstate av) { mchunkptr old_top; /* incoming value of av->top */ INTERNAL_SIZE_T old_size; /* its size */ char* old_end; /* its end address */
long size; /* arg to first MORECORE or mmap call */ char* brk; /* return value from MORECORE */
long correction; /* arg to 2nd MORECORE call */ char* snd_brk; /* 2nd return val */
INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */ INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */ char* aligned_brk; /* aligned offset into brk */
mchunkptr p; /* the allocated/returned chunk */ mchunkptr remainder; /* remainder from allocation */ unsignedlong remainder_size; /* its size */
/* If have mmap, and the request size meets the mmap threshold, and the system supports mmap, and there are few enough currently allocated mmapped regions, try to directly map this request rather than expanding top. */
if ((unsignedlong)(nb) >= (unsignedlong)(mp_.mmap_threshold) && (mp_.n_mmaps < mp_.n_mmaps_max)) {
char* mm; /* return value from mmap call*/
try_mmap: /* Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used. See the front_misalign handling below, for glibc there is no need for further alignments unless we have have high alignment. */ if (MALLOC_ALIGNMENT == 2 * SIZE_SZ) size = (nb + SIZE_SZ + pagemask) & ~pagemask; else size = (nb + SIZE_SZ + MALLOC_ALIGN_MASK + pagemask) & ~pagemask; tried_mmap = true;
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) {
mm = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, 0));
if (mm != MAP_FAILED) {
/* The offset to the start of the mmapped region is stored in the prev_size field of the chunk. This allows us to adjust returned start address to meet alignment requirements here and in memalign(), and still be able to compute proper address argument for later munmap in free() and realloc(). */
if (MALLOC_ALIGNMENT == 2 * SIZE_SZ) { /* For glibc, chunk2mem increases the address by 2*SIZE_SZ and MALLOC_ALIGN_MASK is 2*SIZE_SZ-1. Each mmap'ed area is page aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */ assert (((INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK) == 0); front_misalign = 0; } else front_misalign = (INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { correction = MALLOC_ALIGNMENT - front_misalign; p = (mchunkptr)(mm + correction); p->prev_size = correction; set_head(p, (size - correction) |IS_MMAPPED); } else { p = (mchunkptr)mm; set_head(p, size|IS_MMAPPED); }
/* update statistics */
if (++mp_.n_mmaps > mp_.max_n_mmaps) mp_.max_n_mmaps = mp_.n_mmaps;
sum = mp_.mmapped_mem += size; if (sum > (unsignedlong)(mp_.max_mmapped_mem)) mp_.max_mmapped_mem = sum;
/* Precondition: not enough current space to satisfy nb request */ assert((unsignedlong)(old_size) < (unsignedlong)(nb + MINSIZE));
if (av != &main_arena) {
heap_info *old_heap, *heap; size_t old_heap_size;
/* First try to extend the current heap. */ old_heap = heap_for_ptr(old_top); old_heap_size = old_heap->size; if ((long) (MINSIZE + nb - old_size) > 0 && grow_heap(old_heap, MINSIZE + nb - old_size) == 0) { av->system_mem += old_heap->size - old_heap_size; arena_mem += old_heap->size - old_heap_size; set_head(old_top, (((char *)old_heap + old_heap->size) - (char *)old_top) | PREV_INUSE); } elseif ((heap = new_heap(nb + (MINSIZE + sizeof(*heap)), mp_.top_pad))) { /* Use a newly allocated heap. */ heap->ar_ptr = av; heap->prev = old_heap; av->system_mem += heap->size; arena_mem += heap->size; /* Set up the new top. */ top(av) = chunk_at_offset(heap, sizeof(*heap)); set_head(top(av), (heap->size - sizeof(*heap)) | PREV_INUSE);
/* Setup fencepost and free the old top chunk with a multiple of MALLOC_ALIGNMENT in size. */ /* The fencepost takes at least MINSIZE bytes, because it might become the top chunk again later. Note that a footer is set up, too, although the chunk is marked in use. */ old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK; set_head(chunk_at_offset(old_top, old_size + 2*SIZE_SZ), 0|PREV_INUSE); if (old_size >= MINSIZE) { set_head(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)|PREV_INUSE); set_foot(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)); set_head(old_top, old_size|PREV_INUSE|NON_MAIN_ARENA); _int_free(av, old_top, 1); } else { set_head(old_top, (old_size + 2*SIZE_SZ)|PREV_INUSE); set_foot(old_top, (old_size + 2*SIZE_SZ)); } } elseif (!tried_mmap) /* We can at least try to use to mmap memory. */ goto try_mmap;
} else { /* av == main_arena */
/* Request enough space for nb + pad + overhead */
size = nb + mp_.top_pad + MINSIZE;
/* If contiguous, we can subtract out existing space that we hope to combine with new space. We add it back later only if we don't actually get contiguous space. */
if (contiguous(av)) size -= old_size;
/* Round to a multiple of page size. If MORECORE is not contiguous, this ensures that we only call it with whole-page arguments. And if MORECORE is contiguous and this is not first time through, this preserves page-alignment of previous calls. Otherwise, we correct to page-align below. */
size = (size + pagemask) & ~pagemask;
/* Don't try to call MORECORE if argument is so big as to appear negative. Note that since mmap takes size_t arg, it may succeed below even if we cannot call MORECORE. */
if (size > 0) brk = (char*)(MORECORE(size));
if (brk != (char*)(MORECORE_FAILURE)) { /* Call the `morecore' hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) (); } else { /* If have mmap, try using it as a backup when MORECORE fails or cannot be used. This is worth doing on systems that have "holes" in address space, so sbrk cannot extend to give contiguous space, but space is available elsewhere. Note that we ignore mmap max count and threshold limits, since the space will not be used as a segregated mmap region. */
/* Cannot merge with old top, so add its size back in */ if (contiguous(av)) size = (size + old_size + pagemask) & ~pagemask;
/* If we are relying on mmap as backup, then use larger units */ if ((unsignedlong)(size) < (unsignedlong)(MMAP_AS_MORECORE_SIZE)) size = MMAP_AS_MORECORE_SIZE;
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) {
/* We do not need, and cannot use, another sbrk call to find end */ brk = mbrk; snd_brk = brk + size;
/* Record that we no longer have a contiguous sbrk region. After the first time mmap is used as backup, we do not ever rely on contiguous space since this could incorrectly bridge regions. */ set_noncontiguous(av); } } }
if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (have_fastchunks(av)) malloc_consolidate(av);
if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold)) systrim(mp_.top_pad, av); #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av));
staticint shrink_heap(heap_info *h, long diff) { long new_size;
new_size = (long)h->size - diff; if(new_size < (long)sizeof(*h)) return-1; /* Try to re-map the extra heap space freshly to save memory, and make it inaccessible. See malloc-sysdep.h to know when this is true. */ if (__builtin_expect (check_may_shrink_heap (), 0)) { if((char *)MMAP((char *)h + new_size, diff, PROT_NONE, MAP_FIXED) == (char *) MAP_FAILED) return-2; h->mprotect_size = new_size; } else __madvise ((char *)h + new_size, diff, MADV_DONTNEED); /*fprintf(stderr, "shrink %p %08lx\n", h, new_size);*/
h->size = new_size; return0; }
/* Delete a heap. */
#define delete_heap(heap) \ do {\ if ((char *)(heap) + HEAP_MAX_SIZE == aligned_heap_area)\ aligned_heap_area = NULL;\ __munmap((char*)(heap), HEAP_MAX_SIZE);\ } while (0)
typedefstructglobal_State { .... lu_mem Y_GCmemnogc; /* memory size of nogc linked list */ GCObject *Y_nogc; /* list of objects not to be traversed or collected */ .... }
structUpVal { TValue *v; /* points to stack or to its own value */ lu_mem refcount; /* reference counter */ union { struct {/* (when open) */ UpVal *next; /* linked list */ int touched; /* mark to avoid cycles with dead threads */ } open; TValue value; /* the value (when closed) */ } u; };
staticintluaB_pcall(lua_State *L) { int status; luaL_checkany(L, 1); lua_pushboolean(L, 1); /* first result if no errors */ lua_insert(L, 1); /* put it in place */ status = lua_pcallk(L, lua_gettop(L) - 2, LUA_MULTRET, 0, 0, finishpcall); return finishpcall(L, status, 0); }
LUA_API void lua_xmove(lua_State *from, lua_State *to, int n) { int i; .... from->top -= n; for (i = 0; i < n; i++) { setobj2s(to, to->top, from->top + i); to->top++; /* stack already checked by previous 'api_check' */ } lua_unlock(to); }
staticintluaB_cocreate(lua_State *L) { lua_State *NL; luaL_checktype(L, 1, LUA_TFUNCTION); NL = lua_newthread(L); lua_pushvalue(L, 1); /* move function to top */ lua_xmove(L, NL, 1); /* move function from L to NL */ return1; }
staticintauxresume(lua_State *L, lua_State *co, int narg) { int status; if (!lua_checkstack(co, narg)) { lua_pushliteral(L, "too many arguments to resume"); return-1; /* error flag */ } if (lua_status(co) == LUA_OK && lua_gettop(co) == 0) { lua_pushliteral(L, "cannot resume dead coroutine"); return-1; /* error flag */ }
lua_xmove(L, co, narg); status = lua_resume(co, L, narg); if (status == LUA_OK || status == LUA_YIELD) { int nres = lua_gettop(co); if (!lua_checkstack(L, nres + 1)) { lua_pop(co, nres); /* remove results anyway */ lua_pushliteral(L, "too many results to resume"); return-1; /* error flag */ } lua_xmove(co, L, nres); /* move yielded values */ return nres; } else { lua_xmove(co, L, 1); /* move error message */ return-1; /* error flag */ } }
staticvoidfinishCcall(lua_State *L, int status) { CallInfo *ci = L->ci; int n; /* must have a continuation and must be able to call it */ lua_assert(ci->u.c.k != NULL && L->nny == 0); /* error status can only happen in a protected call */ lua_assert((ci->callstatus & CIST_YPCALL) || status == LUA_YIELD); if (ci->callstatus & CIST_YPCALL) { /* was inside a pcall? */ ci->callstatus &= ~CIST_YPCALL; /* continuation is also inside it */ L->errfunc = ci->u.c.old_errfunc; /* with the same error function */ } /* finish 'lua_callk'/'lua_pcall'; CIST_YPCALL and 'errfunc' already handled */ adjustresults(L, ci->nresults); lua_unlock(L); n = (*ci->u.c.k)(L, status, ci->u.c.ctx); /* call continuation function */ lua_lock(L); api_checknelems(L, n); luaD_poscall(L, ci, L->top - n, n); /* finish 'luaD_precall' */ }
staticvoidunroll(lua_State *L, void *ud) { if (ud != NULL) /* error status? */ finishCcall(L, *(int *)ud); /* finish 'lua_pcallk' callee */ while (L->ci != &L->base_ci) { /* something in the stack */ if (!isLua(L->ci)) /* C function? */ finishCcall(L, LUA_YIELD); /* complete its execution */ else { /* Lua function */ luaV_finishOp(L); /* finish interrupted instruction */ luaV_execute(L); /* execute down to higher C 'boundary' */ } } }
structLClosure *cache;/* last-created closure with this prototype */ GCObject *gclist; } Proto;
我们更关注的是 Upvalues。
Upvalues
upvalue 主要由 一个union 和 TValue 构成,在这里要理解一个概念。
upvalue 的 open 状态。
open:当我们说一个 upvalue 是 open 的,指的是这个 upvalue 其原始值还在数据栈上(因此这个对象如果是可回收的,则被扫描标记管理)。
close:如果说一个 upvalue 是 close 的,指的是这个 upvalue 已经不在栈上了,离开了作用域,会被拷贝到 UpVal.u.value 中,不受到垃圾回收的管控,而是被引用计数管理。
1 2 3 4 5 6 7 8 9 10 11 12 13
structUpVal { TValue *v; /* points to stack or to its own value */ lu_mem refcount; /* reference counter */ union { struct {/* (when open) */ UpVal *next; /* linked list */ int touched; /* mark to avoid cycles with dead threads */ } open; TValue value; /* the value (when closed) */ } u; };
#define upisopen(up)((up)->v != &(up)->u.value)
因此 当 upvalue 为 open 时,v 指向 栈上原始值的地址。反之,则将其值存入到 UpVal 这个结构体自身。
这也就是为什么 下面的代码能够正确执行的原因。
1 2 3 4 5 6 7
functionCounter() local t = 0 returnfunction() t = t + 1 return t end end
return 回去这个 function 因为 t 已经不在栈上了,故将其值存入了这个 UpVal 结构体中,跟随着这个 function 一起。
结构中的 open 这一个结构体,则是当 UpVal 为 open态时,链接上所有的 open UpVal,方便后续的查找,而 touched 是为了防止垃圾回收时 还指向栈上对象的 upvalue 被清理。因为 垃圾回收的 atomic 有个 remarkupval 的函数,在里面进行重新标记 upvalue 。
Closure
无论是 C 函数,还是 Lua 函数,其 UpValues 都与函数本身分离,但又被包裹在一个结构体中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
typedefstructCClosure { ClosureHeader; lua_CFunction f; TValue upvalue[1]; /* list of upvalues */ } CClosure;
typedefstructLClosure { ClosureHeader; structProto *p; UpVal *upvals[1]; /* list of upvalues */ } LClosure;
staticvoidpushclosure(lua_State *L, Proto *p, UpVal **encup, StkId base, StkId ra) { int nup = p->sizeupvalues; Upvaldesc *uv = p->upvalues; int i; LClosure *ncl = luaF_newLclosure(L, nup); ncl->p = p; setclLvalue(L, ra, ncl); /* anchor new closure in stack */ for (i = 0; i < nup; i++) { /* fill in its upvalues */ if (uv[i].instack) /* upvalue refers to local variable? */ ncl->upvals[i] = luaF_findupval(L, base + uv[i].idx); else/* get upvalue from enclosing function */ ncl->upvals[i] = encup[uv[i].idx]; ncl->upvals[i]->refcount++; /* new closure is white, so we do not need a barrier here */ } if (!isblack(p)) /* cache will not break GC invariant? */ p->cache = ncl; /* save it on cache for reuse */ }
UpVal *luaF_findupval(lua_State *L, StkId level) { UpVal **pp = &L->openupval; UpVal *p; UpVal *uv; lua_assert(isintwups(L) || L->openupval == NULL); while (*pp != NULL && (p = *pp)->v >= level) { lua_assert(upisopen(p)); if (p->v == level) /* found a corresponding upvalue? */ return p; /* return it */ pp = &p->u.open.next; } /* not found: create a new upvalue */ uv = luaM_new(L, UpVal); uv->refcount = 0; uv->u.open.next = *pp; /* link it to list of open upvalues */ uv->u.open.touched = 1; *pp = uv; uv->v = level; /* current value lives in the stack */ if (!isintwups(L)) { /* thread not in list of threads with upvalues? */ L->twups = G(L)->twups; /* link it to the list */ G(L)->twups = L; } return uv; }
TString *luaS_newlstr(lua_State *L, constchar *str, size_t l) { GCObject *o; unsignedint h = cast(unsignedint, l); /* seed */ size_t step = (l>>5)+1; /* if string is too long, don't hash all its chars */ size_t l1; for (l1=l; l1>=step; l1-=step) /* compute hash */ h = h ^ ((h<<5)+(h>>2)+cast(unsignedchar, str[l1-1])); for (o = G(L)->strt.hash[lmod(h, G(L)->strt.size)]; o != NULL; o = gch(o)->next) { TString *ts = rawgco2ts(o); if (h == ts->tsv.hash && ts->tsv.len == l && (memcmp(str, getstr(ts), l * sizeof(char)) == 0)) { if (isdead(G(L), o)) /* string is dead (but was not collected yet)? */ changewhite(o); /* resurrect it */ return ts; } } return newlstr(L, str, l, h); /* not found; create a new string */ }
Lua 5.3.6 随机生成随机数种子。
1 2 3 4 5 6 7 8 9 10 11 12
#define luai_makeseed() cast(unsigned int, time(NULL)) // create the seed staticunsignedintmakeseed(lua_State* L) { char buff[4 * sizeof(size_t)]; unsignedint h = luai_makeseed(); int p = 0; addbuff(buff, p, L); /* heap variable */ addbuff(buff, p, &h); /* local variable */ addbuff(buff, p, luaO_nilobject); /* global variable */ addbuff(buff, p, &lua_newstate); /* public function */ return luaS_hash(buff, p, h); }
typedefstructTable { .... lu_byte flags; /* 1<<p means tagmethod(p) is not present */ lu_byte lsizenode; /* log2 of size of 'node' array */// 以2为底表示哈希表大小 unsignedint sizearray; /* size of 'array' array */ TValue *array; /* array part */ Node *node; Node *lastfree; /* any free position is before this position */ structTable *metatable; .... } Table;
数组部分没什么好看的,我们主要看其哈希表的实现。 TKey 中的 nk 主要是用来当Key的哈希值相同时,开链用。
1 2 3 4 5 6 7 8 9 10 11 12
typedefunionTKey { struct { TValuefields; int next; /* for chaining (offset for next node) */ } nk; TValue tvk; } TKey;
staticvoidsetnodevector(lua_State *L, Table *t, unsignedint size) { if (size == 0) { /* no elements to hash part? */ t->node = cast(Node *, dummynode); /* use common 'dummynode' */ t->lsizenode = 0; t->lastfree = NULL; /* signal that it is using dummy node */ } .... }
vmcase(OP_SETLIST) { int n = GETARG_B(i); int c = GETARG_C(i); unsignedint last; Table *h; if (n == 0) n = cast_int(L->top - ra) - 1; if (c == 0) { lua_assert(GET_OPCODE(*ci->u.l.savedpc) == OP_EXTRAARG); c = GETARG_Ax(*ci->u.l.savedpc++); } h = hvalue(ra); last = ((c-1)*LFIELDS_PER_FLUSH) + n; if (last > h->sizearray) /* needs more space? */ luaH_resizearray(L, h, last); /* preallocate it at once */ for (; n > 0; n--) { TValue *val = ra+n; luaH_setint(L, h, last--, val); luaC_barrierback(L, h, val); } L->top = ci->top; /* correct top (in case of previous open call) */ vmbreak; }
TValue *luaH_newkey(lua_State *L, Table *t, const TValue *key) { Node *mp; TValue aux; if (ttisnil(key)) luaG_runerror(L, "table index is nil"); elseif (ttisfloat(key)) { lua_Integer k; if (luaV_tointeger(key, &k, 0)) { /* does index fit in an integer? */ setivalue(&aux, k); key = &aux; /* insert it as an integer */ } elseif (luai_numisnan(fltvalue(key))) luaG_runerror(L, "table index is NaN"); } mp = mainposition(t, key); if (!ttisnil(gval(mp)) || isdummy(t)) { /* main position is taken? */ Node *othern; Node *f = getfreepos(t); /* get a free place */ if (f == NULL) { /* cannot find a free place? */ rehash(L, t, key); /* grow table */ /* whatever called 'newkey' takes care of TM cache */ return luaH_set(L, t, key); /* insert key into grown table */ } lua_assert(!isdummy(t)); othern = mainposition(t, gkey(mp)); if (othern != mp) { /* is colliding node out of its main position? */ /* yes; move colliding node into free position */ while (othern + gnext(othern) != mp) /* find previous */ othern += gnext(othern); gnext(othern) = cast_int(f - othern); /* rechain to point to 'f' */ *f = *mp; /* copy colliding node into free pos. (mp->next also goes) */ if (gnext(mp) != 0) { gnext(f) += cast_int(mp - f); /* correct 'next' */ gnext(mp) = 0; /* now 'mp' is free */ } setnilvalue(gval(mp)); } else { /* colliding node is in its own main position */ /* new node will go into free position */ if (gnext(mp) != 0) gnext(f) = cast_int((mp + gnext(mp)) - f); /* chain new position */ else lua_assert(gnext(f) == 0); gnext(mp) = cast_int(f - mp); mp = f; } } setnodekey(L, &mp->i_key, key); luaC_barrierback(L, t, key); lua_assert(ttisnil(gval(mp))); return gval(mp); }
staticvoidrehash(lua_State *L, Table *t, const TValue *ek) { unsignedint asize; /* optimal size for array part */ unsignedint na; /* number of keys in the array part */ unsignedint nums[MAXABITS + 1]; int i; int totaluse; for (i = 0; i <= MAXABITS; i++) nums[i] = 0; /* reset counts */ na = numusearray(t, nums); /* count keys in array part */ totaluse = na; /* all those keys are integer keys */ totaluse += numusehash(t, nums, &na); /* count keys in hash part */ /* count extra key */ na += countint(ek, nums); totaluse++; /* compute new size for array part */ asize = computesizes(nums, &na); /* resize the table to new computed sizes */ luaH_resize(L, t, asize, totaluse - na); }
static lua_Unsigned unbound_search(Table *t, lua_Unsigned j) { lua_Unsigned i = j; /* i is zero or a present index */ j++; /* find 'i' and 'j' such that i is present and j is not */ while (!ttisnil(luaH_getint(t, j))) { i = j; if (j > l_castS2U(LUA_MAXINTEGER) / 2) { /* overflow? */ /* table was built with bad purposes: resort to linear search */ i = 1; while (!ttisnil(luaH_getint(t, i))) i++; return i - 1; } j *= 2; } /* now do a binary search between them */ while (j - i > 1) { lua_Unsigned m = (i+j)/2; if (ttisnil(luaH_getint(t, m))) j = m; else i = m; } return i; }
lua_Unsigned luaH_getn(Table *t) { unsignedint j = t->sizearray; if (j > 0 && ttisnil(&t->array[j - 1])) { /* there is a boundary in the array part: (binary) search for it */ unsignedint i = 0; while (j - i > 1) { unsignedint m = (i+j)/2; if (ttisnil(&t->array[m - 1])) j = m; else i = m; } return i; } /* else must find a boundary in hash part */ elseif (isdummy(t)) /* hash part is empty? */ return j; /* that is easy... */ elsereturn unbound_search(t, j); }
intluaH_next(lua_State *L, Table *t, StkId key) { unsignedint i = findindex(L, t, key); /* find original element */ for (; i < t->sizearray; i++) { /* try first array part */ if (!ttisnil(&t->array[i])) { /* a non-nil value? */ setivalue(key, i + 1); setobj2s(L, key+1, &t->array[i]); return1; } } for (i -= t->sizearray; cast_int(i) < sizenode(t); i++) { /* hash part */ if (!ttisnil(gval(gnode(t, i)))) { /* a non-nil value? */ setobj2s(L, key, gkey(gnode(t, i))); setobj2s(L, key+1, gval(gnode(t, i))); return1; } } return0; /* no more elements */ }
staticunsignedintfindindex(lua_State *L, Table *t, StkId key) { unsignedint i; if (ttisnil(key)) return0; /* first iteration */ i = arrayindex(key); if (i != 0 && i <= t->sizearray) /* is 'key' inside array part? */ return i; /* yes; that's the index */ else { int nx; Node *n = mainposition(t, key); for (;;) { /* check whether 'key' is somewhere in the chain */ /* key may be dead already, but it is ok to use it in 'next' */ if (luaV_rawequalobj(gkey(n), key) || (ttisdeadkey(gkey(n)) && iscollectable(key) && deadvalue(gkey(n)) == gcvalue(key))) { i = cast_int(n - gnode(t, 0)); /* key index in hash table */ /* hash elements are numbered after array ones */ return (i + 1) + t->sizearray; } nx = gnext(n); if (nx == 0) luaG_runerror(L, "invalid key to 'next'"); /* key not found */ else n += nx; } } }
typedefstructCallInfo { StkId func; /* function index in the stack */ StkIdtop; /* top for this function */ structCallInfo *previous, *next;/* dynamic call link */ union { struct {/* only for Lua functions */ StkId base; /* base for this function */ const Instruction *savedpc; } l; struct {/* only for C functions */ lua_KFunction k; /* continuation in case of yields */ ptrdiff_t old_errfunc; lua_KContext ctx; /* context info. in case of yields */ } c; } u; ptrdiff_t extra; short nresults; /* expected number of results from this function */ unsignedshort callstatus; } CallInfo;
structlua_State { .... unsignedshort nci; /* number of items in 'ci' list */ StkId top; /* first free slot in the stack */ .... CallInfo *ci; /* call info for current function */ StkId stack_last; /* last free slot in the stack */ StkId stack; /* stack base */ .... };
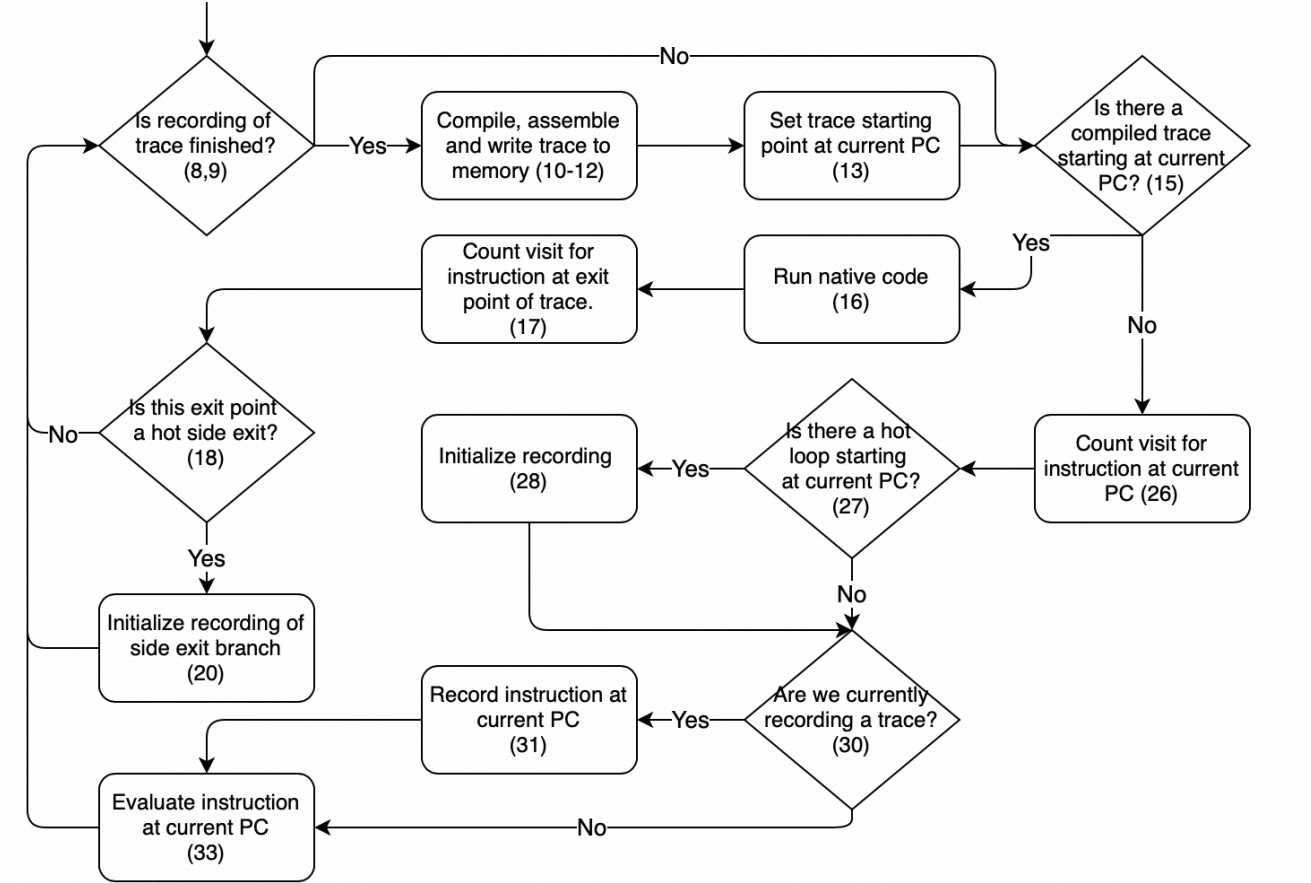
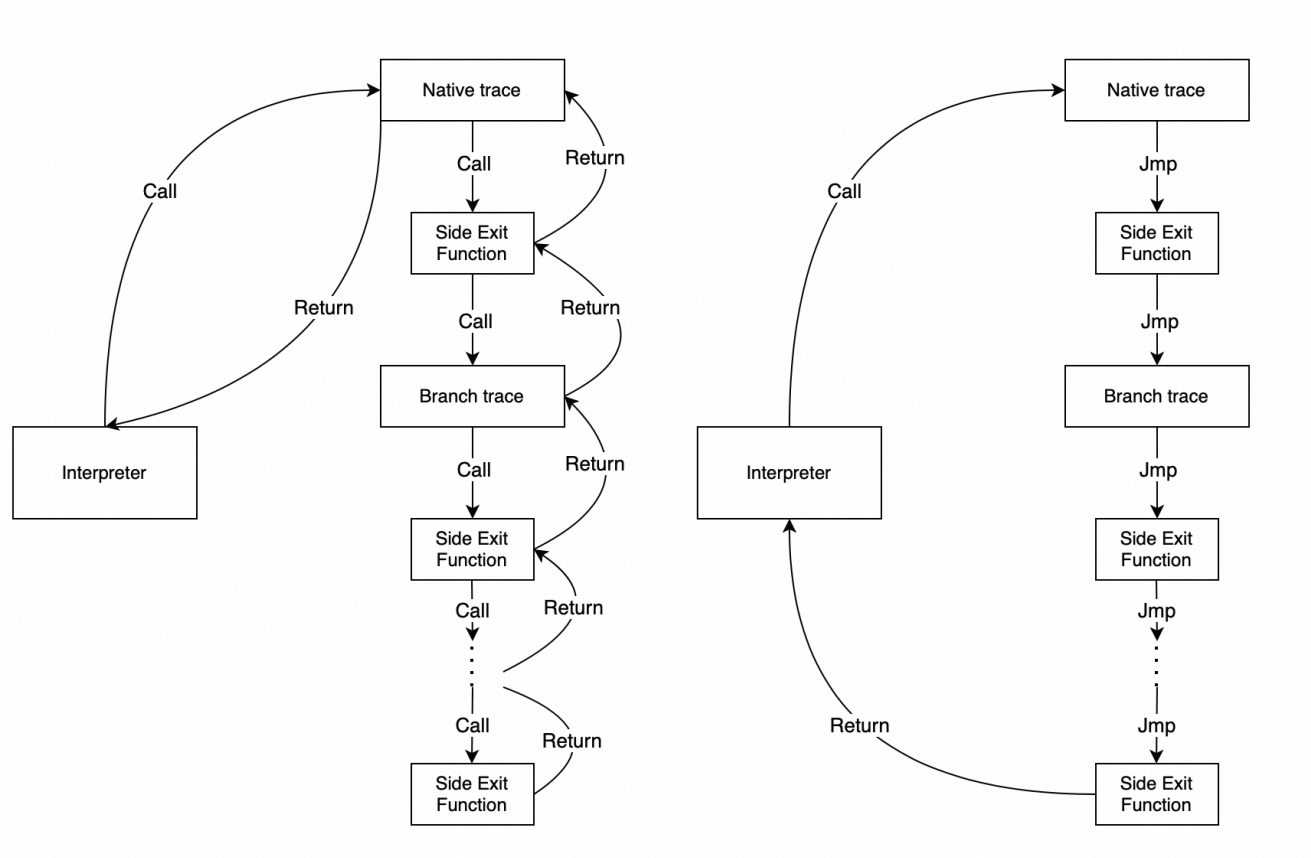
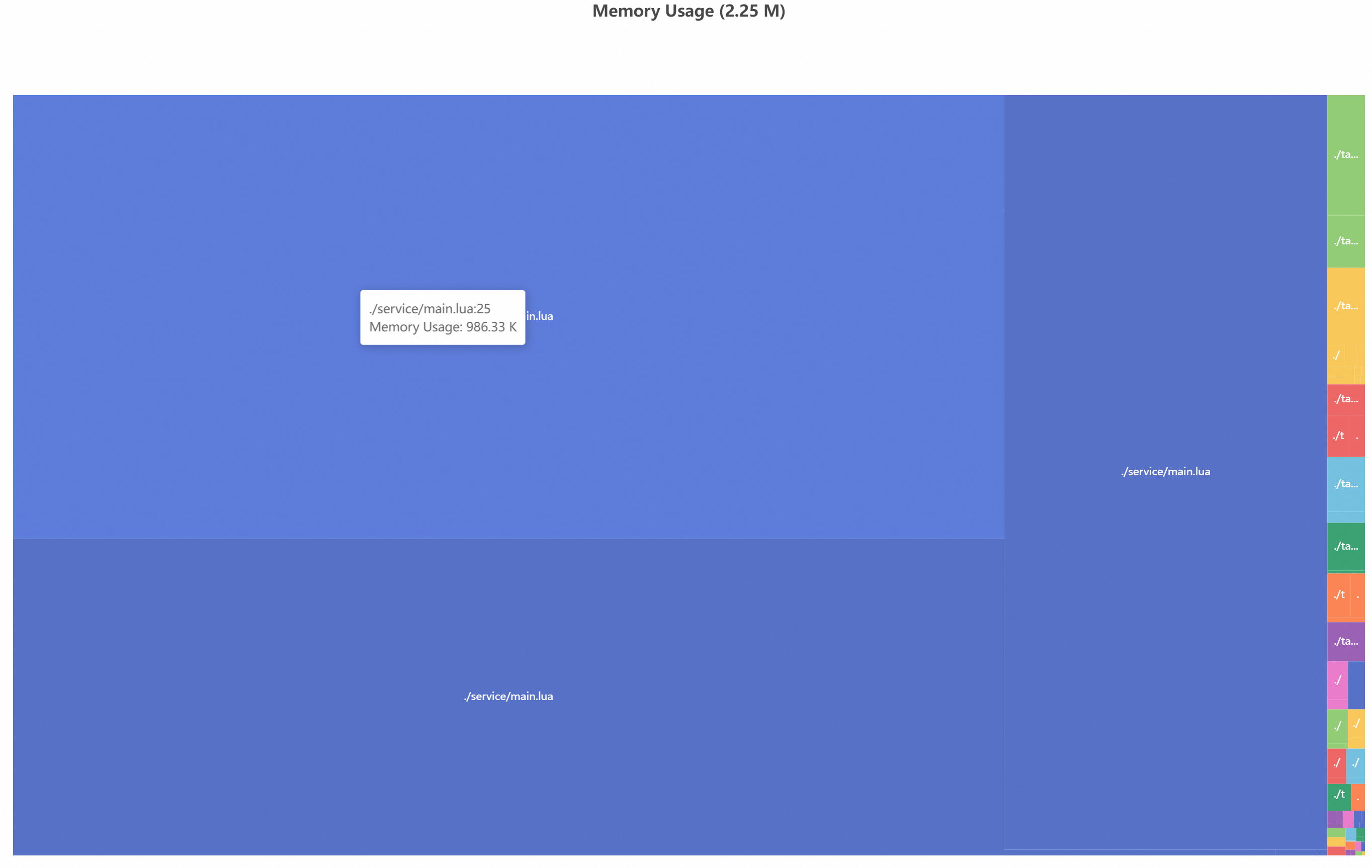
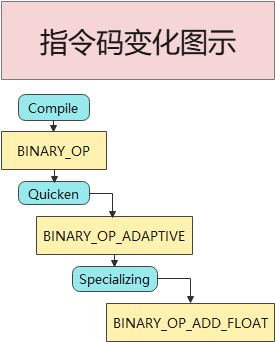
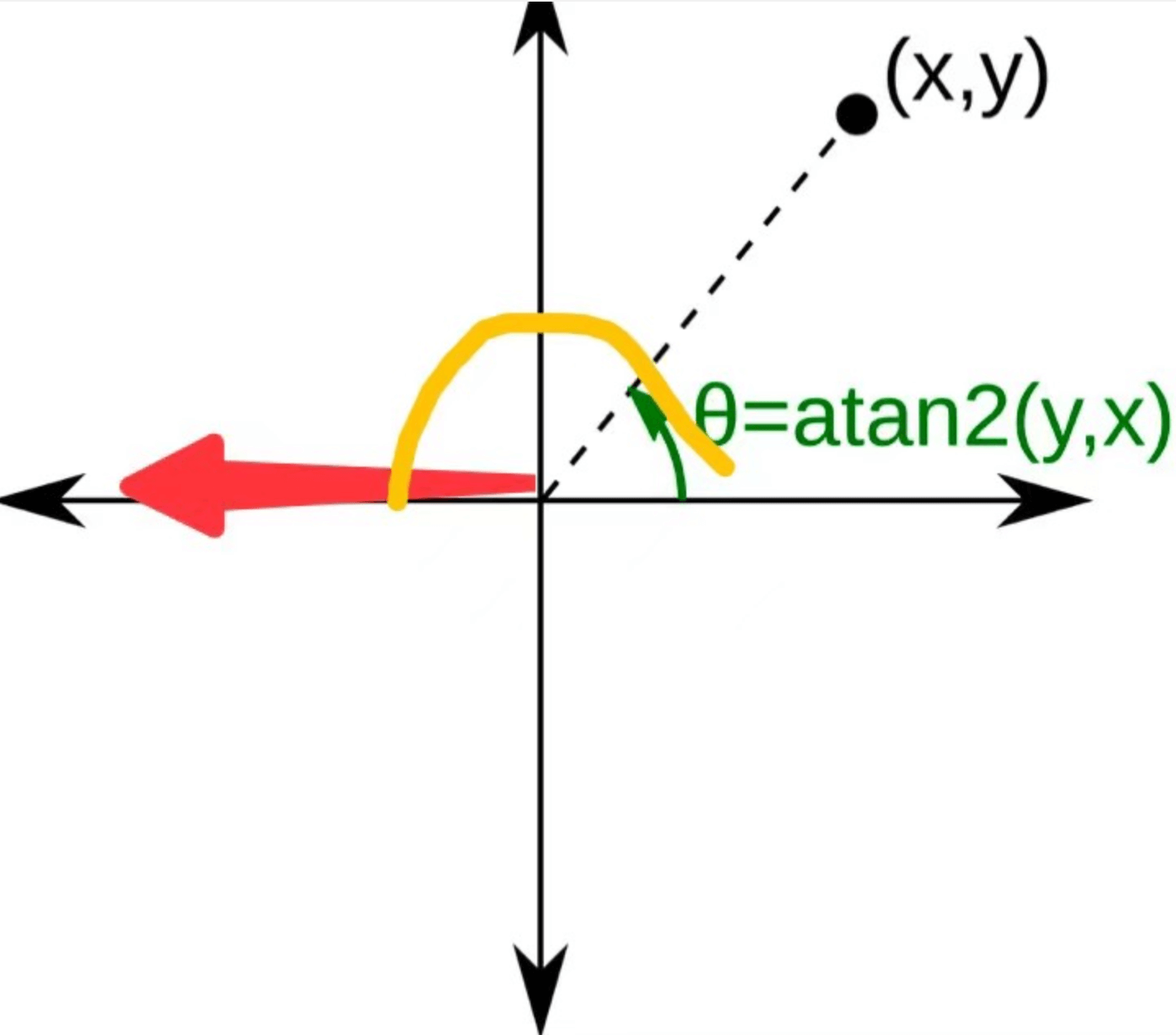
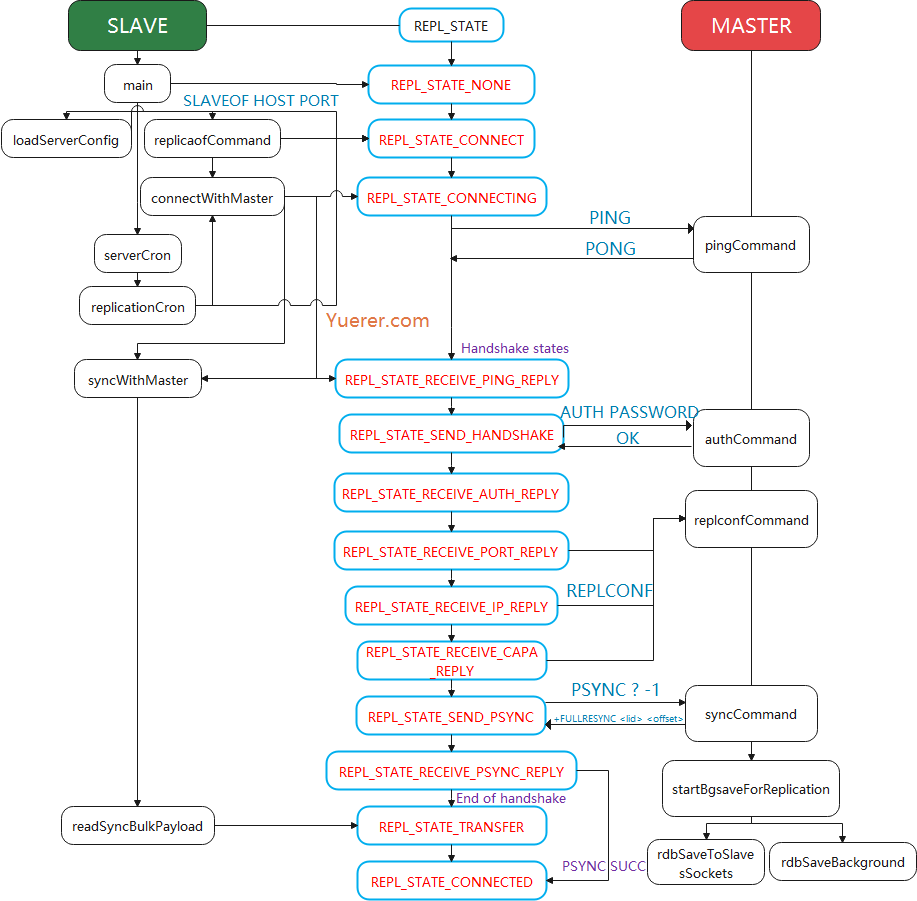
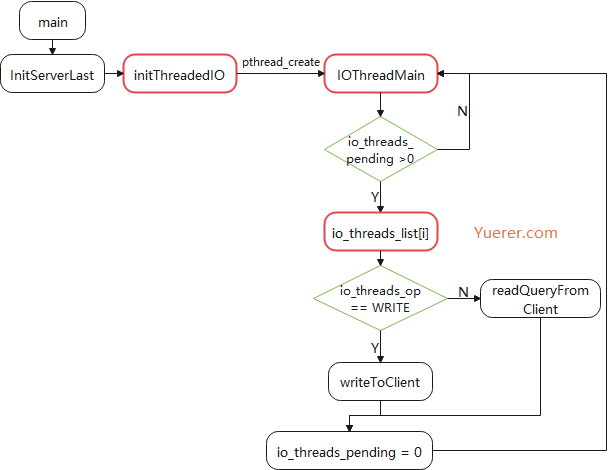
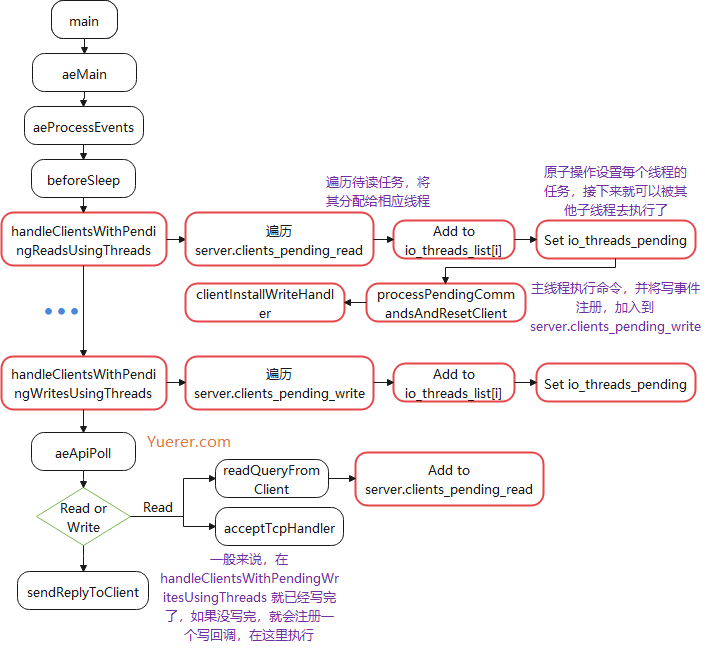
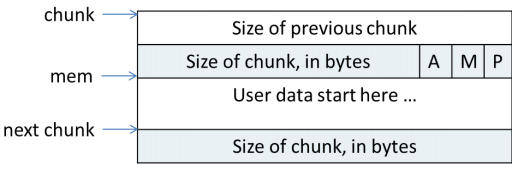
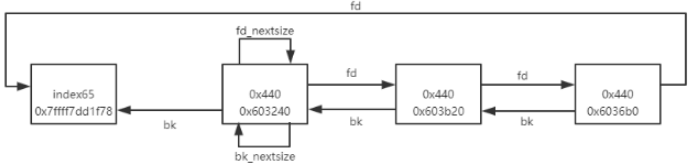
.png)