/* The corresponding word size */ #define SIZE_SZ (sizeof(INTERNAL_SIZE_T))
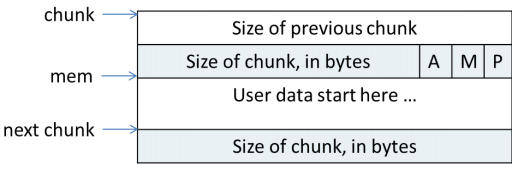
structmalloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ // ----------------------------------------------------------------------- structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;
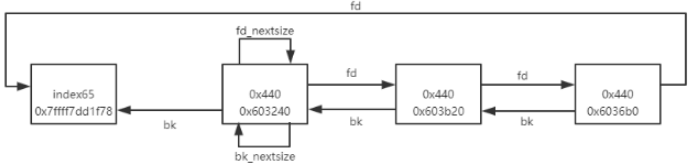
/* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
/* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */ #define PREV_INUSE 0x1 /* extract inuse bit of previous chunk */ #define prev_inuse(p) ((p)->size & PREV_INUSE) /* size field is or'ed with IS_MMAPPED if the chunk was obtained with mmap() */ #define IS_MMAPPED 0x2 /* check for mmap()'ed chunk */ #define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained from a non-main arena. This is only set immediately before handing the chunk to the user, if necessary. */ #define NON_MAIN_ARENA 0x4
/* check for chunk from non-main arena */ #define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA)
/* Memory map support */ int n_mmaps; int n_mmaps_max; int max_n_mmaps; /* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */ int no_dyn_threshold;
/* Statistics */ INTERNAL_SIZE_T mmapped_mem; /*INTERNAL_SIZE_T sbrked_mem;*/ /*INTERNAL_SIZE_T max_sbrked_mem;*/ INTERNAL_SIZE_T max_mmapped_mem; INTERNAL_SIZE_T max_total_mem; /* only kept for NO_THREADS */
/* First address handed out by MORECORE/sbrk. */ char* sbrk_base; };
若到这一步要么是 还没找到合适的内存,或者是 chunk_size 是一个 大的请求,则先遍历 fast bins,将相邻的 chunk 进行合并,放入到 unsorted bin 中,从 unstorted bin 中进行查找,一边找一边将其放入正确的 bins 中,同时在 binmap中进行标记。如果找到则返回给用户,若 unsorted bin 只有一个 chunk,且 该 chunk 为 last remainder chunk,且我们需要的是一个 small bin chunk,则将其切分,剩余部分依然不动,此步骤最多尝试 MAX_ITERS(10000)次,防止因为 unsored bin 的 chunk 过多而影响分配效率。
最后还是找不到,那就在 large bins 中按照最佳匹配的原则,从更大的 bins 中进行查找,查找方式是通过遍历 binmap,找一个合适的 chunk,并将其切分,成功则返回,否则下一步。
只好从 top chunk 进行切分了(回收的时候也是从 top chunk 进行切分,埋下了长周期的内存无法回收导致内存暴涨的伏笔),不成功下一步。
又开始打 fast bins 的注意了,主要是 fast bins 回收的时候没有加锁,而是采用 lock-free 方式(Compareand-Swap)回收,因此有可能里面已经有 chunk 了,这时候又开始合并,放入 unsorted bin,但是却是从 small bins 或从 large bins 中再去查找,这主要是因为,在第 5,6 步的时候,如果在 small bins 中找不到合适的 chunk,就合并 fast bins 到 unsorted bin,然后放回到指定的 small bins 和 large bins 中,但是并没有再去扫描一下相应的 bins,这里相当于再补上一刀。
a = get_free_list (); if (a == NULL) { /* Nothing immediately available, so generate a new arena. */ if (narenas_limit == 0) { if (mp_.arena_max != 0) narenas_limit = mp_.arena_max; elseif (narenas > mp_.arena_test) { int n = __get_nprocs ();
if (n >= 1) narenas_limit = NARENAS_FROM_NCORES (n); else /* We have no information about the system. Assume two cores. */ narenas_limit = NARENAS_FROM_NCORES (2); } } repeat:; size_t n = narenas; /* NB: the following depends on the fact that (size_t)0 - 1 is a very large number and that the underflow is OK. If arena_max is set the value of arena_test is irrelevant. If arena_test is set but narenas is not yet larger or equal to arena_test narenas_limit is 0. There is no possibility for narenas to be too big for the test to always fail since there is not enough address space to create that many arenas. */ if (__builtin_expect (n <= narenas_limit - 1, 0)) { if (catomic_compare_and_exchange_bool_acq (&narenas, n + 1, n)) goto repeat; a = _int_new_arena (size); if (__builtin_expect (a == NULL, 0)) catomic_decrement (&narenas); } else a = reused_arena (avoid_arena); } #else if(!a_tsd) a = a_tsd = &main_arena; else { a = a_tsd->next; if(!a) { /* This can only happen while initializing the new arena. */ (void)mutex_lock(&main_arena.mutex); THREAD_STAT(++(main_arena.stat_lock_wait)); return &main_arena; } }
/* Check the global, circularly linked list for available arenas. */ bool retried = false; repeat: do { if(!mutex_trylock(&a->mutex)) { if (retried) (void)mutex_unlock(&list_lock); THREAD_STAT(++(a->stat_lock_loop)); tsd_setspecific(arena_key, (void *)a); return a; } a = a->next; } while(a != a_tsd);
/* If not even the list_lock can be obtained, try again. This can happen during `atfork', or for example on systems where thread creation makes it temporarily impossible to obtain _any_ locks. */ if(!retried && mutex_trylock(&list_lock)) { /* We will block to not run in a busy loop. */ (void)mutex_lock(&list_lock);
/* Since we blocked there might be an arena available now. */ retried = true; a = a_tsd; goto repeat; }
/* Nothing immediately available, so generate a new arena. */ a = _int_new_arena(size); (void)mutex_unlock(&list_lock); #endif
staticvoid* _int_malloc(mstate av, size_t bytes) { INTERNAL_SIZE_T nb; /* normalized request size */ unsignedint idx; /* associated bin index */ mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */ INTERNAL_SIZE_T size; /* its size */ int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */ unsignedlong remainder_size; /* its size */
unsignedint block; /* bit map traverser */ unsignedint bit; /* bit map traverser */ unsignedintmap; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */ mchunkptr bck; /* misc temp for linking */
constchar *errstr = NULL;
/* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */
checked_request2size(bytes, nb);
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
else { idx = largebin_index(nb); if (have_fastchunks(av)) malloc_consolidate(av); }
/* Process recently freed or remaindered chunks, taking one only if it is exact fit, or, if this a small request, the chunk is remainder from the most recent non-exact fit. Place other traversed chunks in bins. Note that this step is the only place in any routine where chunks are placed in bins. The outer loop here is needed because we might not realize until near the end of malloc that we should have consolidated, so must do so and retry. This happens at most once, and only when we would otherwise need to expand memory to service a "small" request. */
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */
/* maintain large bins in sorted order */ if (fwd != bck) { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert((bck->bk->size & NON_MAIN_ARENA) == 0); if ((unsignedlong)(size) < (unsignedlong)(bck->bk->size)) { fwd = bck; bck = bck->bk;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last(bin) && victim->size == victim->fd->size) victim = victim->fd;
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; } /* Split */ else { remainder = chunk_at_offset(victim, nb); /* We cannot assume the unsorted list is empty and therefore have to perform a complete insert here. */ bck = unsorted_chunks(av); fwd = bck->fd; if (__builtin_expect (fwd->bk != bck, 0)) { errstr = "malloc(): corrupted unsorted chunks"; goto errout; } remainder->bk = bck; remainder->fd = fwd; bck->fd = remainder; fwd->bk = remainder; if (!in_smallbin_range(remainder_size)) { remainder->fd_nextsize = NULL; remainder->bk_nextsize = NULL; } set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); set_foot(remainder, remainder_size); } check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); if (__builtin_expect (perturb_byte, 0)) alloc_perturb (p, bytes); return p; } }
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected. The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */
++idx; bin = bin_at(av,idx); block = idx2block(idx); map = av->binmap[block]; bit = idx2bit(idx);
for (;;) {
/* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ( (map = av->binmap[block]) == 0);
bin = bin_at(av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0) { bin = next_bin(bin); bit <<= 1; assert(bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last(bin);
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin(bin); bit <<= 1; }
else { size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */ assert((unsignedlong)(size) >= (unsignedlong)(nb));
remainder_size = size - nb;
/* unlink */ unlink(victim, bck, fwd);
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset(victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; }
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations). We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */
第八步,从 top chunk 中进行切分,回收也是从 top chunk 从高往低释放回给内核,因此如果后分配的没有释放,会导致先分配的已释放都没办法还回给内核。
1 2 3 4 5 6 7 8 9 10
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks(av)) { malloc_consolidate(av); /* restore original bin index */ if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); }
staticvoid* sysmalloc(INTERNAL_SIZE_T nb, mstate av) { mchunkptr old_top; /* incoming value of av->top */ INTERNAL_SIZE_T old_size; /* its size */ char* old_end; /* its end address */
long size; /* arg to first MORECORE or mmap call */ char* brk; /* return value from MORECORE */
long correction; /* arg to 2nd MORECORE call */ char* snd_brk; /* 2nd return val */
INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */ INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */ char* aligned_brk; /* aligned offset into brk */
mchunkptr p; /* the allocated/returned chunk */ mchunkptr remainder; /* remainder from allocation */ unsignedlong remainder_size; /* its size */
/* If have mmap, and the request size meets the mmap threshold, and the system supports mmap, and there are few enough currently allocated mmapped regions, try to directly map this request rather than expanding top. */
if ((unsignedlong)(nb) >= (unsignedlong)(mp_.mmap_threshold) && (mp_.n_mmaps < mp_.n_mmaps_max)) {
char* mm; /* return value from mmap call*/
try_mmap: /* Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used. See the front_misalign handling below, for glibc there is no need for further alignments unless we have have high alignment. */ if (MALLOC_ALIGNMENT == 2 * SIZE_SZ) size = (nb + SIZE_SZ + pagemask) & ~pagemask; else size = (nb + SIZE_SZ + MALLOC_ALIGN_MASK + pagemask) & ~pagemask; tried_mmap = true;
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) {
mm = (char*)(MMAP(0, size, PROT_READ|PROT_WRITE, 0));
if (mm != MAP_FAILED) {
/* The offset to the start of the mmapped region is stored in the prev_size field of the chunk. This allows us to adjust returned start address to meet alignment requirements here and in memalign(), and still be able to compute proper address argument for later munmap in free() and realloc(). */
if (MALLOC_ALIGNMENT == 2 * SIZE_SZ) { /* For glibc, chunk2mem increases the address by 2*SIZE_SZ and MALLOC_ALIGN_MASK is 2*SIZE_SZ-1. Each mmap'ed area is page aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */ assert (((INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK) == 0); front_misalign = 0; } else front_misalign = (INTERNAL_SIZE_T)chunk2mem(mm) & MALLOC_ALIGN_MASK; if (front_misalign > 0) { correction = MALLOC_ALIGNMENT - front_misalign; p = (mchunkptr)(mm + correction); p->prev_size = correction; set_head(p, (size - correction) |IS_MMAPPED); } else { p = (mchunkptr)mm; set_head(p, size|IS_MMAPPED); }
/* update statistics */
if (++mp_.n_mmaps > mp_.max_n_mmaps) mp_.max_n_mmaps = mp_.n_mmaps;
sum = mp_.mmapped_mem += size; if (sum > (unsignedlong)(mp_.max_mmapped_mem)) mp_.max_mmapped_mem = sum;
/* Precondition: not enough current space to satisfy nb request */ assert((unsignedlong)(old_size) < (unsignedlong)(nb + MINSIZE));
if (av != &main_arena) {
heap_info *old_heap, *heap; size_t old_heap_size;
/* First try to extend the current heap. */ old_heap = heap_for_ptr(old_top); old_heap_size = old_heap->size; if ((long) (MINSIZE + nb - old_size) > 0 && grow_heap(old_heap, MINSIZE + nb - old_size) == 0) { av->system_mem += old_heap->size - old_heap_size; arena_mem += old_heap->size - old_heap_size; set_head(old_top, (((char *)old_heap + old_heap->size) - (char *)old_top) | PREV_INUSE); } elseif ((heap = new_heap(nb + (MINSIZE + sizeof(*heap)), mp_.top_pad))) { /* Use a newly allocated heap. */ heap->ar_ptr = av; heap->prev = old_heap; av->system_mem += heap->size; arena_mem += heap->size; /* Set up the new top. */ top(av) = chunk_at_offset(heap, sizeof(*heap)); set_head(top(av), (heap->size - sizeof(*heap)) | PREV_INUSE);
/* Setup fencepost and free the old top chunk with a multiple of MALLOC_ALIGNMENT in size. */ /* The fencepost takes at least MINSIZE bytes, because it might become the top chunk again later. Note that a footer is set up, too, although the chunk is marked in use. */ old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK; set_head(chunk_at_offset(old_top, old_size + 2*SIZE_SZ), 0|PREV_INUSE); if (old_size >= MINSIZE) { set_head(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)|PREV_INUSE); set_foot(chunk_at_offset(old_top, old_size), (2*SIZE_SZ)); set_head(old_top, old_size|PREV_INUSE|NON_MAIN_ARENA); _int_free(av, old_top, 1); } else { set_head(old_top, (old_size + 2*SIZE_SZ)|PREV_INUSE); set_foot(old_top, (old_size + 2*SIZE_SZ)); } } elseif (!tried_mmap) /* We can at least try to use to mmap memory. */ goto try_mmap;
} else { /* av == main_arena */
/* Request enough space for nb + pad + overhead */
size = nb + mp_.top_pad + MINSIZE;
/* If contiguous, we can subtract out existing space that we hope to combine with new space. We add it back later only if we don't actually get contiguous space. */
if (contiguous(av)) size -= old_size;
/* Round to a multiple of page size. If MORECORE is not contiguous, this ensures that we only call it with whole-page arguments. And if MORECORE is contiguous and this is not first time through, this preserves page-alignment of previous calls. Otherwise, we correct to page-align below. */
size = (size + pagemask) & ~pagemask;
/* Don't try to call MORECORE if argument is so big as to appear negative. Note that since mmap takes size_t arg, it may succeed below even if we cannot call MORECORE. */
if (size > 0) brk = (char*)(MORECORE(size));
if (brk != (char*)(MORECORE_FAILURE)) { /* Call the `morecore' hook if necessary. */ void (*hook) (void) = force_reg (__after_morecore_hook); if (__builtin_expect (hook != NULL, 0)) (*hook) (); } else { /* If have mmap, try using it as a backup when MORECORE fails or cannot be used. This is worth doing on systems that have "holes" in address space, so sbrk cannot extend to give contiguous space, but space is available elsewhere. Note that we ignore mmap max count and threshold limits, since the space will not be used as a segregated mmap region. */
/* Cannot merge with old top, so add its size back in */ if (contiguous(av)) size = (size + old_size + pagemask) & ~pagemask;
/* If we are relying on mmap as backup, then use larger units */ if ((unsignedlong)(size) < (unsignedlong)(MMAP_AS_MORECORE_SIZE)) size = MMAP_AS_MORECORE_SIZE;
/* Don't try if size wraps around 0 */ if ((unsignedlong)(size) > (unsignedlong)(nb)) {
/* We do not need, and cannot use, another sbrk call to find end */ brk = mbrk; snd_brk = brk + size;
/* Record that we no longer have a contiguous sbrk region. After the first time mmap is used as backup, we do not ever rely on contiguous space since this could incorrectly bridge regions. */ set_noncontiguous(av); } } }
if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (have_fastchunks(av)) malloc_consolidate(av);
if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold)) systrim(mp_.top_pad, av); #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av));
staticint shrink_heap(heap_info *h, long diff) { long new_size;
new_size = (long)h->size - diff; if(new_size < (long)sizeof(*h)) return-1; /* Try to re-map the extra heap space freshly to save memory, and make it inaccessible. See malloc-sysdep.h to know when this is true. */ if (__builtin_expect (check_may_shrink_heap (), 0)) { if((char *)MMAP((char *)h + new_size, diff, PROT_NONE, MAP_FIXED) == (char *) MAP_FAILED) return-2; h->mprotect_size = new_size; } else __madvise ((char *)h + new_size, diff, MADV_DONTNEED); /*fprintf(stderr, "shrink %p %08lx\n", h, new_size);*/
h->size = new_size; return0; }
/* Delete a heap. */
#define delete_heap(heap) \ do { \ if ((char *)(heap) + HEAP_MAX_SIZE == aligned_heap_area) \ aligned_heap_area = NULL; \ __munmap((char*)(heap), HEAP_MAX_SIZE); \ } while (0)