Lua 内存监控工具
背景
Lua 项目中,通常需要工具进行内存监控,目前开源的工具中有 lua-snapshot,但这个工具的缺陷是开销比较大,在调用接口之后,会扫描整个GC链表,找出所有的GC对象,并进行统计,最后会创建大量的 Lua 对象,将结果存在里面,这就会导致本身内存已经够高了,再用这个工具的话,很可能会触发 OOM 或者是 STW,业务无法正常提供服务。
作为补充,期望有个工具能够监控所有的对象开辟的位置和大小信息,进行精确定位代码问题。
最终实现的效果如下图所示:
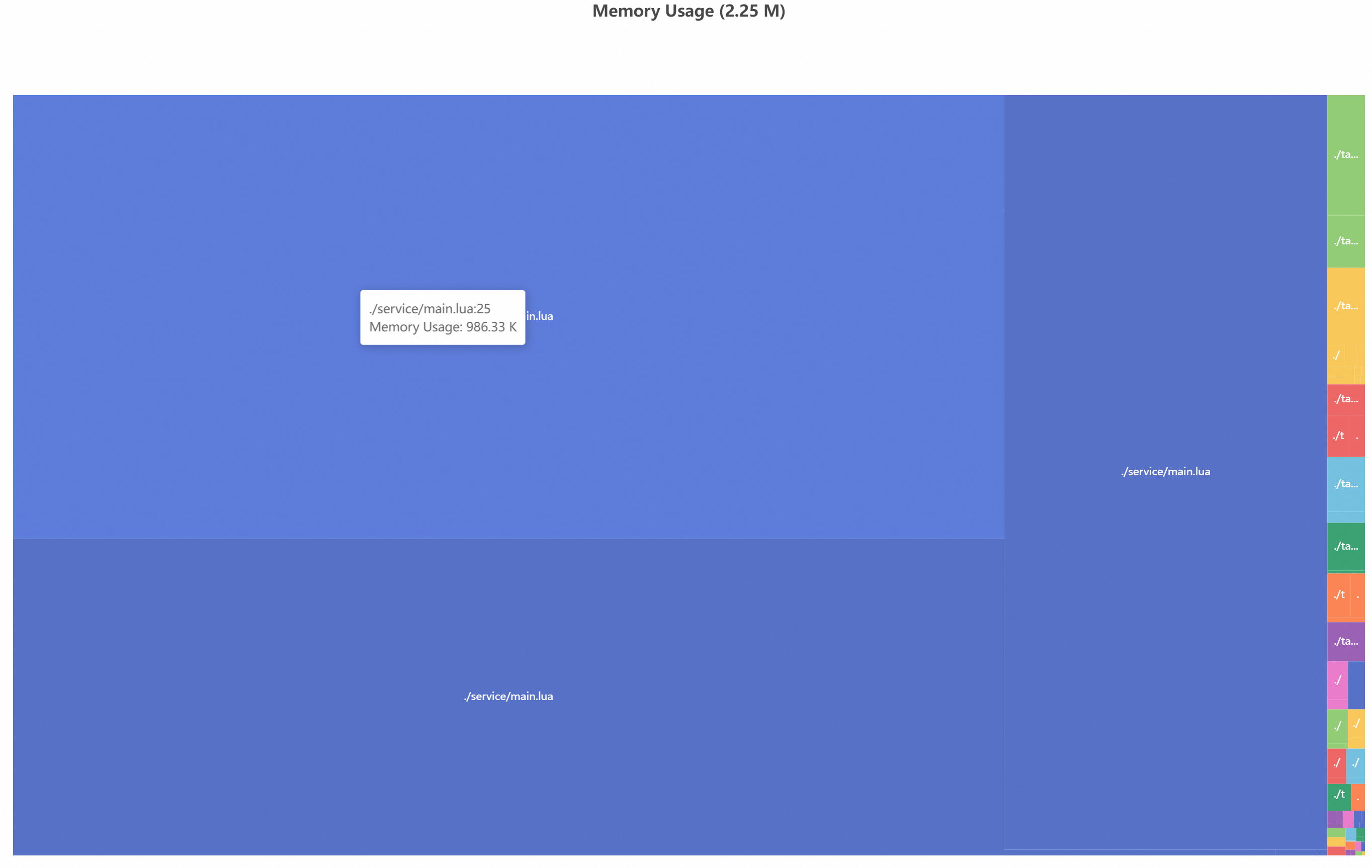
实现
Lua 支持替换 frealloc,这就使得我们监控内存分配成为了可能,接下来就是如何减轻性能损耗的同时将信息记录下来。我们需要的信息有 文件名 和 行号。
内存分配
Lua 中所有的内存分配都是基于 realloc ,可以简单的在分配时,遍历 CallInfo 调用栈,获取最顶层的 Lua 函数的文件名和行号,将其记录下来即可。
内存释放
由于对象释放时,是找不到正确的 Lua 调用栈的(就算找到了,也是取到触发垃圾回收那个时刻的文件名和行号),因此需要再分配时,就给这个内存对象记录一下,为了快速方便的取得该内存地址的开辟位置,在内存对象上增加一个 Cookie 。
1 | struct mem_cookie { |
内存扩缩容
内存扩缩容,大部分情况下都是 table 下的 array 或者 hash 部分进行扩缩容,若直接在扩缩容处获取调用栈信息,会导致获取的文件名和行号对不上该 table 创建的位置,在 global_State 记录 table pointer,通过读 Cookie,避免遍历调用栈以及更精确。
文件名优化
我们采用 proto_id作为文件名,这主要是出于以下考虑:
- proto 可能会被释放,不可传递 proto->source 指针。
- proto->source 字符串拷贝会比较消耗性能。
因此通过给 proto 一个 ID,进行编号,映射一张 proto_id -> source 的表,即可。具体可以改动 loadfile 的实现完成。
行号优化
Lua 5.4 中行号是相对行号,内存分配又是个高频操作,将 Lua 5.3 的绝对行号移植过来,直接查表省去行号计算。