ptmalloc2 内存管理
近期在压测服务器的过程中发现内存随着用户数增加而暴涨,用户数减少内存却没有释放回内核,一开始怀疑是内存泄漏,后面上了工具排查,最终定位到是 glibc 的内存管理并没有将内存释放给OS,为了解决这个问题,对 ptmalloc2 进行了剖析。
本篇中,不谈论 brk 和 mmap 系统调用的使用方法,默认环境为 Linux-x86-64,讨论的 ptmalloc2 的版本为 glibc 2.17 的版本。
chunk
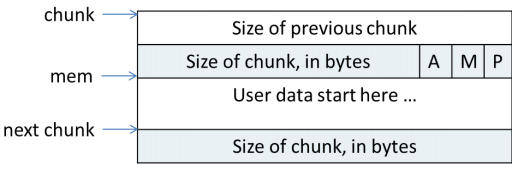
ptmalloc2 分配给用户的内存都以 chunk 来表示,可以理解为 chunk 为分配释放内存的载体。
1 |
|
chunk 由以上几部分组成, INTERNAL_SIZE_T 为 size_t 为了屏蔽平台之间的差异,这里只谈论64位平台,为8字节。
prev_size代表着上一个 chunk 的大小,是否有效取决于size的属性位P。size代表当前 chunk 的大小和属性,其中低3位为属性位[A|M|P]。- 当这个 chunk 为空闲时,则会使用
fd, bk将其加入链表中管理。 - 同上,
fd_nextsize bk_nextsize只用在large bin中,表示 上/下一个大小的指针,加快链表遍历。