UE5 的垃圾回收(GC)采用 标记-清除(Mark & Sweep) 策略,通过遍历对象引用关系确定可达对象并清理其余内存。本文聚焦 UE5.6 的 增量垃圾回收,尤其是 增量标记(Incremental Marking) 的最新变化,以及 工程上实现该算法的优化。阅读前如已熟悉通用 GC 原理(例如 Lua 的三色标记),会更易理解 UE 的实现细节与优化策略。
从 STW 到 增量扫描
在 UE5.4 之前,GC 的可达性分析通常以 一次性完成(Stop-the-World) 的方式进行:扫描阶段暂停游戏逻辑,实现简单,但缺点是 停顿时间可能较长,带来 Gameplay 卡顿。
从 UE5.4 起,引擎引入 增量扫描:将可达性分析拆分到多帧执行,平滑每帧的 GC 开销。这引出了一个核心问题:
扫描间隙产生的新对象/新引用如何处理?
对象分配
对象通过 NewObject 分配时,会进入 UObjectBase 构造并注册到全局对象表 GUObjectArray:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| UObjectBase::UObjectBase(UClass* InClass,
EObjectFlags InFlags,
EInternalObjectFlags InInternalFlags,
UObject *InOuter,
FName InName,
int32 InInternalIndex,
int32 InSerialNumber,
FRemoteObjectId InRemoteId)
: ObjectFlags(InFlags)
, InternalIndex(INDEX_NONE)
, ClassPrivate(InClass)
, OuterPrivate(InOuter)
{
AddObject(InName, InInternalFlags, InInternalIndex, InSerialNumber, InRemoteId);
}
|
AddObject 会把对象注册到 GUObjectArray 并设置内部标志位:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| void UObjectBase::AddObject(FName InName, EInternalObjectFlags InSetInternalFlags, int32 InInternalIndex, int32 InSerialNumber, FRemoteObjectId InRemoteId)
{
NamePrivate = InName;
EInternalObjectFlags InternalFlagsToSet = InSetInternalFlags;
if (!IsInGameThread())
{
InternalFlagsToSet |= EInternalObjectFlags::Async;
}
if (ObjectFlags & RF_MarkAsRootSet)
{
InternalFlagsToSet |= EInternalObjectFlags::RootSet;
ObjectFlags &= ~RF_MarkAsRootSet;
}
if (ObjectFlags & RF_MarkAsNative)
{
InternalFlagsToSet |= EInternalObjectFlags::Native;
ObjectFlags &= ~RF_MarkAsNative;
}
GUObjectArray.AllocateUObjectIndex(this, InternalFlagsToSet, InInternalIndex, InSerialNumber, InRemoteId);
HashObject(this);
}
|
在 AllocateUObjectIndex 中,可见关键点:非 “DisregardForGC” 窗口下,新对象会被标上 “Reachable” 位,即默认可达:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| void FUObjectArray::AllocateUObjectIndex(UObjectBase* Object, EInternalObjectFlags InitialFlags, int32 AlreadyAllocatedIndex, int32 SerialNumber, FRemoteObjectId RemoteId)
{
LockInternalArray();
FUObjectItem* ObjectItem = IndexToObject(Index);
ObjectItem->Flags = (int32)EInternalObjectFlags::PendingConstruction;
if (!(IsOpenForDisregardForGC() & GUObjectArray.DisregardForGCEnabled()))
{
ObjectItem->Flags |= (int32)UE::GC::Private::FGCFlags::GetReachableFlagValue_ForGC();
}
ObjectItem->SetObject(Object);
ObjectItem->RefCount = 0;
ObjectItem->ClusterRootIndex = 0;
ObjectItem->SerialNumber = SerialNumber;
Object->InternalIndex = Index;
if (InitialFlags != EInternalObjectFlags::None)
{
ObjectItem->ThisThreadAtomicallySetFlag(InitialFlags);
}
UnlockInternalArray();
}
|
关键结构与概念
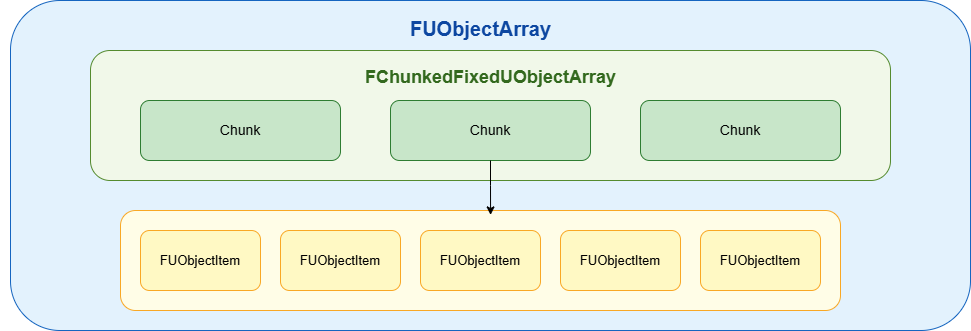
GUObjectArray(全局对象表)
采用 分块(Chunked)固定容量 的方式保存 FUObjectItem,每块 65536 个元素,保证槽位地址稳定(GC 经常拿指针,避免动态扩容带来的迁移):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| extern COREUOBJECT_API FUObjectArray GUObjectArray;
class FUObjectArray
{
typedef FChunkedFixedUObjectArray TUObjectArray;
TUObjectArray ObjObjects;
};
class FChunkedFixedUObjectArray
{
enum
{
NumElementsPerChunk = 64 * 1024,
};
FUObjectItem** Objects;
FUObjectItem* PreAllocatedObjects;
};
|
![]()
FUObjectItem(对象条目)
为每个 UObject 提供 GC 所需的元数据:内部 Flags、簇信息、序列号、强引用计数等。
每个 UObject 实例都会对应一个 FUObjectItem 结构。
这里的 union 是一种空间优化技巧,由于 UObject 地址 8 字节对齐(低 3 位恒为 0),引擎通过拆分高低位来压缩存储(但默认没开启,所以读者可以忽略)。
Flags 是 EInternalObjectFlags 从 UObjectFlags 中提取出来的一些垃圾回收关键 Flags,这是为了少解引用一次 UObject ,减少 Cache Miss。
1
2
3
4
5
6
7
8
9
10
11
12
| struct FUObjectItem
{
union
{
class UObjectBase* Object = nullptr;
uint32 ObjectPtrLow;
};
int32 Flags;
int32 ClusterRootIndex;
int32 SerialNumber;
int32 RefCount;
};
|
Disregard 区(非 GC 对象区)
引擎初始化阶段开启 IsOpenForDisregardForGC() 时,允许分配 不参与 GC 的对象,之后 GC 会跳过此区段扫描。
![]()
Cluster(簇)
将强相关对象聚合为 簇。当扫描到 簇根 时,可一次性把整簇标记为可达,显著降低图遍历成本。
对象赋值(写屏障)
在增量扫描间隙,游戏逻辑可能会发生引用写入:
如果 A 已扫描、B 尚未标记,B 可能被误扫为垃圾。为解决该一致性问题,自 UE5.4 起,推荐使用 TObjectPtr 以启用 写屏障,而非原生裸指针:
1
2
3
4
5
| UPROPERTY()
AMyWeapon* Weapon;
UPROPERTY()
TObjectPtr<AMyWeapon> Weapon;
|
当我们执行:
1
| MyActor->Weapon = NewWeapon;
|
底层会自动触发写屏障,从而让 GC 识别到新引用关系,并将其标记为可达。
TObjectPtr 包含 FObjectPtr ,可以看到这个类其实啥也没做,写屏障放到了 FObjectPtr 里实现。
当开启垃圾回收屏障时 UE_OBJECT_PTR_GC_BARRIER,需要提供自定义的构造函数和赋值运算符来让类型变成非平凡(non-trivial)的赋值类型,从而阻止编译器用 memcpy/memmove 绕过构造函数/赋值运算符。
后续将直接给出开启垃圾回收屏障版本的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| template <typename T>
struct TObjectPtr
{
public:
using ElementType = T;
#if UE_OBJECT_PTR_GC_BARRIER
[[nodiscard]] TObjectPtr(TObjectPtr<T>&& Other)
: ObjectPtr(MoveTemp(Other.ObjectPtr))
{
}
[[nodiscard]] TObjectPtr(const TObjectPtr<T>& Other)
: ObjectPtr(Other.ObjectPtr)
{
}
#else
[[nodiscard]] TObjectPtr(TObjectPtr<T>&& Other) = default;
TObjectPtr(const TObjectPtr<T>& Other) = default;
#endif
#if UE_OBJECT_PTR_GC_BARRIER
TObjectPtr<T>& operator=(TObjectPtr<T>&& Other)
{
ObjectPtr = MoveTemp(Other.ObjectPtr);
return *this;
}
TObjectPtr<T>& operator=(const TObjectPtr<T>& Other)
{
ObjectPtr = Other.ObjectPtr;
return *this;
}
#else
TObjectPtr<T>& operator=(TObjectPtr<T>&&) = default;
TObjectPtr<T>& operator=(const TObjectPtr<T>&) = default;
#endif
private:
FObjectPtr ObjectPtr;
};
|
可以看出实际做写屏障在 FObjectPtr 的构造/赋值处触发:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| struct FObjectPtr
{
mutable FObjectHandle Handle;
[[nodiscard]] explicit FORCEINLINE FObjectPtr(UObject* Object)
: Handle(UE::CoreUObject::Private::MakeObjectHandle(Object))
{
ConditionallyMarkAsReachable(Object);
}
FORCEINLINE void ConditionallyMarkAsReachable(const UObject* InObj) const
{
if (UE::GC::GIsIncrementalReachabilityPending && InObj)
{
UE::GC::MarkAsReachable(InObj);
}
}
};
|
当 增量可达性分析进行中(GIsIncrementalReachabilityPending 为真)且发生新引用写入时,写屏障会把对象推入“新起点”容器,用于后续继续扫描:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| static TExpandingChunkedList<UObject*> GReachableObjects;
static TExpandingChunkedList<FUObjectItem*> GReachableClusters;
FORCEINLINE static void MarkObjectItemAsReachable(FUObjectItem* ObjectItem)
{
if (FGCFlags::MarkAsReachableInterlocked_ForGC(ObjectItem))
{
if (ObjectItem->GetOwnerIndex() >= 0)
{
GReachableObjects.Push(static_cast<UObject*>(ObjectItem->GetObject()));
}
else
{
GReachableClusters.Push(ObjectItem);
}
}
}
|
增量 GC
GC 的增量标记与增量清理由引擎 tick 推进:
1
2
3
4
| void UWorld::Tick( ELevelTick TickType, float DeltaSeconds )
{
GEngine->ConditionalCollectGarbage();
}
|
当至少一个 World 已经 BegunPlay 则进入回收逻辑,优先推进增量扫描(可达性分析),其次增量清理。
- 优先推进增量扫描(Reachability Analysis)。
- 若扫描/清理都不需推进,且时间达到阈值,则执行一轮
PerformGarbageCollectionAndCleanupActors。 - 否则继续 IncrementalPurge(增量清理)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| void UEngine::ConditionalCollectGarbage()
{
if (GFrameCounter != LastGCFrame)
{
if (bHasAWorldBegunPlay)
{
TimeSinceLastPendingKillPurge += FApp::GetDeltaTime();
const float TimeBetweenPurgingPendingKillObjects = GetTimeBetweenGarbageCollectionPasses(bHasPlayersConnected);
if (bShouldDelayGarbageCollect)
{
bShouldDelayGarbageCollect = false;
}
else if (IsIncrementalReachabilityAnalysisPending())
{
PerformIncrementalReachabilityAnalysis(GetReachabilityAnalysisTimeLimit());
}
else if (!IsIncrementalPurgePending()
&& (TimeSinceLastPendingKillPurge > TimeBetweenPurgingPendingKillObjects) && TimeBetweenPurgingPendingKillObjects > 0.f)
{
PerformGarbageCollectionAndCleanupActors();
}
else
{
float IncGCTime = GetIncrementalGCTimePerFrame();
IncrementalPurgeGarbage(true, IncGCTime);
}
}
LastGCFrame = GFrameCounter;
}
else if (IsIncrementalReachabilityAnalysisPending())
{
PerformIncrementalReachabilityAnalysis(GetReachabilityAnalysisTimeLimit());
}
}
|
假设是第一次进入垃圾回收,所以没有增量扫描也没有增量清理且时间还没到达两次 GC 的间隔,于是前 N 帧都会反复进入 IncrementalPurgeGarbage,但因为实在没有垃圾,直接返回,相当于空转。
直到时间阈值达到,正式进入到 PerformGarbageCollectionAndCleanupActors 中,此时先尝试做垃圾回收,并尝试清理挂在 UWorld 上的 Actor 指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void UEngine::PerformGarbageCollectionAndCleanupActors()
{
TGuardValue<bool> _FullGC(bGCPerformingFullPurge, bForcePurge);
if (TryCollectGarbage(GARBAGE_COLLECTION_KEEPFLAGS, bForcePurge))
{
ForEachObjectOfClass(UWorld::StaticClass(), [](UObject* World)
{
CastChecked<UWorld>(World)->CleanupActors();
});
TimeSinceLastPendingKillPurge = 0.0f;
bFullPurgeTriggered = false;
LastGCFrame = GFrameCounter;
}
}
|
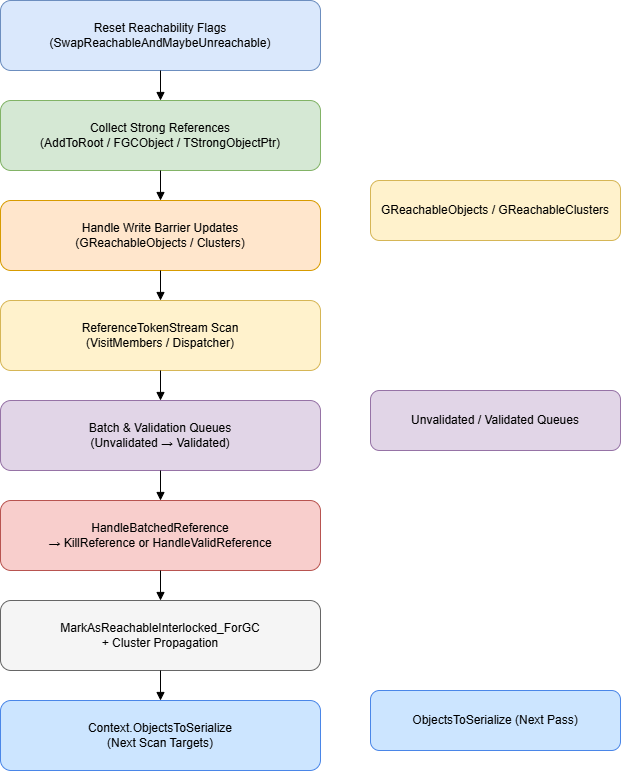
增量扫描(Reachability Pass)
重置可达标记
为了做可达性分析,首先我们要重置所有对象为不可达,在 UE 5.4 之前,确实是通过遍历所有GC对象进行标记的,这就很浪费,熟悉 Lua 的都知道三色标记法,只需要每次扫描之前交换一次当前不可达标记即可,UE 新版本中也确实是这么优化的。
1
2
3
4
5
6
| void MarkObjectsAsUnreachable(const EObjectFlags KeepFlags)
{
FGCFlags::SwapReachableAndMaybeUnreachable();
MarkClusteredObjectsAsReachable(GatherOptions, InitialObjects);
MarkRootObjectsAsReachable(GatherOptions, KeepFlags, InitialObjects);
}
|
此阶段在多线程下执行,先标记:
为 Reachable,减轻后面扫描的工作量。
收集强引用对象
让对象避免被回收的典型方式:
AddToRoot:加入根集。TStrongObjectPtr:增加强引用计数(临时持有)。- 实现
FGCObject::AddReferencedObjects:自定义向 GC 报告引用。 FGCObjectScopeGuard 在指定代码区域内保持对象(基于 FGCObject 实现)。
这也就意味着我们还需要支持第三种,收集该类对象通常由单独线程进行:
1
2
3
4
5
6
7
8
9
10
| void BeginInitialReferenceCollection(EGCOptions Options)
{
InitialReferences.Reset();
if (IsParallel(Options))
{
InitialCollection = UE::Tasks::Launch(TEXT("CollectInitialReferences"),
[&] () { FGCObject::GGCObjectReferencer->AddInitialReferences(InitialReferences); });
}
}
|
增量扫描的写屏障处理
增量扫描间隙业务逻辑还在执行,需要将触发写屏障的新引用对象作为新的扫描起点加入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| void PerformReachabilityAnalysisPass(const EGCOptions Options)
{
FContextPoolScope Pool;
FWorkerContext* Context;
if (!Private::GReachableObjects.IsEmpty())
{
Private::GReachableObjects.PopAllAndEmpty(InitialObjects);
}
else if (GReachabilityState.GetNumIterations() == 0 || (Stats.bFoundGarbageRef && !GReachabilityState.IsSuspended()))
{
Context->InitialNativeReferences = GetInitialReferences(Options);
}
if (!Private::GReachableClusters.IsEmpty())
{
TArray<FUObjectItem*> KeepClusterRefs;
Private::GReachableClusters.PopAllAndEmpty(KeepClusterRefs);
for (FUObjectItem* ObjectItem : KeepClusterRefs)
{
MarkReferencedClustersAsReachable<EGCOptions::None>(ObjectItem->GetClusterIndex(), InitialObjects);
}
}
Context->SetInitialObjectsUnpadded(InitialObjects);
PerformReachabilityAnalysisOnObjects(Context, Options);
}
|
GReachableObjects 与 GReachableClusters 分别保存新对象和新簇根。
该函数每帧执行一次,直到扫描完成。
引用扫描
为了高效地遍历对象引用,UE 会在初始化时(编辑器热重载时)Link 一下,为每个 UClass 构建 ReferenceTokenStream :
1
| Class->AssembleReferenceTokenStream();
|
其思路是:通过反射收集 相对对象首地址的偏移 与 成员类型,序列化为紧凑结构,GC 扫描时只需 顺序解释 即可,避免层层虚调用与递归:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| template<class DispatcherType, typename ObjectType>
FORCEINLINE_DEBUGGABLE void VisitMembers(DispatcherType& Dispatcher, FSchemaView Schema, ObjectType* Instance)
{
const EOrigin Origin = Schema.GetOrigin();
uint64* InstanceCursor = (uint64*)Instance;
uint32 DebugIdx = 0;
for (const FMemberWord* WordIt = Schema.GetWords(); true; ++WordIt)
{
const FMemberWordUnpacked Quad(WordIt->Members);
for (FMemberUnpacked Member : Quad.Members)
{
uint8* MemberPtr = (uint8*)(InstanceCursor + Member.WordOffset);
switch (Member.Type)
{
case EMemberType::Reference: Dispatcher.HandleKillableReference(*(UObject**)MemberPtr, FMemberId(DebugIdx), Origin);
break;
}
}
}
}
|
优点:消除虚函数调用、递归层级与分支预测失败,显著提升 cache 局部性。
标记可达对象
扫描到的引用会进入到 Dispatcher.HandleKillableReference 或 Dispatcher.HandleImmutableReference 中进行标记。
Killable 表示可以清空(可变)的引用。Immutable 表示不可清空(不可变)的引用,比如 Outer、Class。
这个概念设计出来是为了更安全的处理引用,举一个具体的例子:
1
2
3
4
5
6
7
8
| UCLASS()
class AMyActor : public AActor
{
GENERATED_BODY()
public:
UPROPERTY()
TObjectPtr<UInventoryItem> HeldItem;
};
|
当 HeldItem 所指对象被 MarkAsGarbage() 后, GC 会自动清空该 Killable 引用,避免悬空指针。
1
| HeldItem->MarkAsGarbage();
|
这样 HeldItem 就不用总是担心是否野指针,在早期 UE 版本中,只有一个 MarkPendingKill 的概念,这个东西就不会自动去清空所有引用它的地方的指针,已被废弃。
HandleXXXReference 核心都是将其先存起来,批处理化,Prefetch 使用了 _mm_prefetch 函数来预先加载指定对象到 Cache 中。
Killable 引用存储槽位地址以便后续置 null,Immutable 引用只存对象指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| FORCEINLINE_DEBUGGABLE void HandleKillableReference(UObject*& Object, FMemberId MemberId, EOrigin Origin)
{
QueueReference(Context.GetReferencingObject(), Object, MemberId, ProcessorType::MayKill(Origin, true));
}
FORCEINLINE void HandleImmutableReference(UObject* Object, FMemberId MemberId, EOrigin Origin)
{
ImmutableBatcher.PushReference(FImmutableReference{Object});
}
FORCEINLINE_DEBUGGABLE void QueueReference(const UObject* ReferencingObject, UObject*& Object, FMemberId MemberId, EKillable Killable)
{
if (Killable == EKillable::Yes)
{
FPlatformMisc::Prefetch(&Object);
KillableBatcher.PushReference(FMutableReference{&Object});
}
else
{
ImmutableBatcher.PushReference(FImmutableReference{Object});
}
}
|
PushReference 会将其放入 UnvalidatedReferences 队列中,这表示是未经验证的队列,只有经过验证的引用,才会被标记为可达。
队列严格按照 Cache Line 大小对齐,对齐减少多核写竞争:
1
2
| alignas (PLATFORM_CACHE_LINE_SIZE) TBatchQueue<UnvalidatedReferenceType, UnvalidatedBatchSize> UnvalidatedReferences;
alignas (PLATFORM_CACHE_LINE_SIZE) TBatchQueue<ValidatedReferenceType, ValidatedBatchSize, ValidatedPrefetchAhead> ValidatedReferences;
|
CPU 从内存取数据是按固定大小的cache line(常见是 64B)成块搬进来。
只要一个线程写了落在某个 cache line 里的任意字节,这整条 line 在其他核上的副本就要被标记失效
尽量让它们不共享同一条 line,减少互相写入导致的失效。
验证对象是否有效(非 Permanent 且已 Resolved),这个对象既不是永不 GC 的对象,同时该对象又是已经被加载到内存上的(UE允许对象先不加载,占个位,直到 Resolved 后才加载进来分配指针)。
1
2
3
4
5
6
7
8
9
10
11
12
13
| FORCEINLINE_DEBUGGABLE void DrainUnvalidated(const uint32 Num)
{
FPermanentObjectPoolExtents Permanent(PermanentPool);
FValidatedBitmask ValidsA, ValidsB;
for (uint32 Idx = 0; Idx < Num; ++Idx)
ValidsA.Set(Idx, !Permanent.Contains(GetObject(UnvalidatedReferences[Idx])));
for (uint32 Idx = 0; Idx < Num; ++Idx)
ValidsB.Set(Idx, IsObjectHandleResolved_ForGC(reinterpret_cast<FObjectHandle&>(GetObject(UnvalidatedReferences[Idx]))));
FValidatedBitmask Validations = FValidatedBitmask::And(ValidsA, ValidsB);
QueueValidReferences(Validations);
}
|
使用 bitmask 是因为CPU 对分支预测(if 条件)非常敏感。如果CPU 分支预测经常失败,会导致 pipeline flush(流水线清空重排),严重拖慢性能。
经过验证的引用会放入到 ValidatedReferences 队列中。
现在处理 经过验证的引用的队列,依然是预取一些需要的字段,最后交由 HandleBatchedReference 去标记可达。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| FORCEINLINE_DEBUGGABLE void DrainValidated(const uint32 Num)
{
static constexpr uint32 InternalIndexPrefetchOffset = 0;
static constexpr uint32 PrefetchAhead = ValidatedPrefetchAhead;
static constexpr ::size_t OffsetOfFlags = FGCFlags::OffsetOfFlags_ForGC();
for (uint32 Idx = 0; Idx < Num; ++Idx)
{
FPlatformMisc::Prefetch(ValidatedReferences[Idx].Object, InternalIndexPrefetchOffset);
}
for (uint32 Idx = 0; Idx < Num; ++Idx)
{
ObjectIndices[Idx] = GUObjectArray.ObjectToIndex(ValidatedReferences[Idx].Object);
}
FChunkedFixedUObjectArray& ObjectArray = GUObjectArray.GetObjectItemArrayUnsafe();
FReferenceMetadata Metadatas[ValidatedBatchSize + PrefetchAhead];
for (uint32 Idx = 0; Idx < Num; ++Idx)
{
Metadatas[Idx].ObjectItem = ObjectArray.GetObjectPtr(ObjectIndices[Idx]);
}
for (uint32 Idx = 0; Idx < Num; ++Idx)
{
FPlatformMisc::Prefetch(Metadatas[Idx].ObjectItem, OffsetOfFlags);
}
for (uint32 Idx = 0; Idx < Num; ++Idx)
{
Metadatas[Idx].Flags = Metadatas[Idx].ObjectItem->GetFlags();
}
for (uint32 Idx = 0; Idx < Num; ++Idx)
{
ProcessorType::HandleBatchedReference(Context, ValidatedReferences[Idx], Metadatas[Idx]);
}
ValidatedReferences.Num = 0;
}
|
UObjectBase::InternalIndex 实际在 偏移12 上,但这里 InternalIndexPrefetchOffset 却等于 0,这是因为 UObject 按 16B 对齐,而 Cache Line 大小为 64B,所以不需要填入具体的 Offset 也能保证一定会将这个字段包括进来预热,写 0 还能让该机器码更紧凑。
当该对象已经被 MarkAsGarbage() 后,它身上就会多个 EInternalObjectFlags::Garbage 标记,此时就可以找到引用它的地方,给它置空,这就和我们前面的例子对应上了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static constexpr EInternalObjectFlags KillFlag = EInternalObjectFlags::Garbage;
FORCEINLINE_DEBUGGABLE void KillReference(UObject*& Object) { Object = nullptr; }
FORCEINLINE static void HandleBatchedReference(FWorkerContext& Context, FResolvedMutableReference Reference, FReferenceMetadata Metadata)
{
if (Metadata.Has(KillFlag))
{
KillReference(*Reference.Mutable);
}
else
{
HandleValidReference(Context, Reference, Metadata);
}
}
|
否则则进行标记,这时候要考虑多线程的情况,被其他线程提前标记过后 MarkAsReachableInterlocked_ForGC 的情况下会返回 false ,此时只需要考虑该对象是否为簇成员,若是则考虑其簇根是否被递归扫描过,确保将簇与簇之间的引用也标记一遍,也就是说 先遇到簇成员、没遇到根,也能把整簇激活。
其实大部分簇在垃圾回收刚启动时候就会调用 MarkClusteredObjectsAsReachable 将已有的簇标记为可达,并传播下去,所以这里大部分情况下都啥也不做,这就是为什么 簇能加速垃圾回收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| FORCEINLINE static bool HandleValidReference(FWorkerContext& Context, FImmutableReference Reference, FReferenceMetadata Metadata)
{
if (FGCFlags::MarkAsReachableInterlocked_ForGC(Metadata.ObjectItem))
{
if (!Metadata.Has(EInternalObjectFlags::ClusterRoot))
{
Context.ObjectsToSerialize.Add<Options>(Reference.Object);
}
else
{
MarkReferencedClustersAsReachableThunk<Options>(Metadata.ObjectItem->GetClusterIndex(), Context.ObjectsToSerialize);
}
return true;
}
else
{
if ((Metadata.ObjectItem->GetOwnerIndex() > 0) & !Metadata.Has(EInternalObjectFlags::ReachableInCluster))
{
FUObjectItem* RootObjectItem = GUObjectArray.IndexToObjectUnsafeForGC(Metadata.ObjectItem->GetOwnerIndex());
if (FGCFlags::ThisThreadAtomicallySetFlag_ForGC(Metadata.ObjectItem, EInternalObjectFlags::ReachableInCluster))
{
if (FGCFlags::MarkAsReachableInterlocked_ForGC(RootObjectItem))
{
MarkReferencedClustersAsReachableThunk<Options>(RootObjectItem->GetClusterIndex(), Context.ObjectsToSerialize);
}
}
}
}
return false;
}
|
至此我们讲解完了整个垃圾回收的扫描过程,已经将可达的对象全都标记出来了。
收集不可达对象
因为已经找出了所有可达对象,因此所有可能不可达 MaybeUnreachable 的对象都是可以回收的。
多线程迭代所有对象,找出所有可能不可达对象,将其全部标记为不可达。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| bool GatherUnreachableObjects(UE::GC::EGatherOptions Options, double TimeLimit )
{
ParallelFor( TEXT("GC.GatherUnreachable"), GGatherUnreachableObjectsState.NumWorkerThreads(), 1, [&ThreadIterators, &GatherStartTime, &TimeLimit, &TimeLimitExceededFlag](int32 ThreadIndex)
{
constexpr int32 TimeLimitPollInterval = 10;
FTimeSlicer Timer(TimeLimitPollInterval, ThreadIndex * TimeLimitPollInterval, GatherStartTime, TimeLimit, TimeLimitExceededFlag);
FGatherUnreachableObjectsState::FIterator& Iterator = ThreadIterators[ThreadIndex];
while (Iterator.Index <= Iterator.LastIndex)
{
FUObjectItem* ObjectItem = &GUObjectArray.GetObjectItemArrayUnsafe()[Iterator.Index++];
if (FGCFlags::IsMaybeUnreachable_ForGC(ObjectItem))
{
FGCFlags::SetUnreachable(ObjectItem);
Iterator.Payload.Add({ ObjectItem });
}
}
}, (GGatherUnreachableObjectsState.NumWorkerThreads() == 1) ? EParallelForFlags::ForceSingleThread : EParallelForFlags::None);
GGatherUnreachableObjectsState.Finish(GUnreachableObjects);
}
|
![]()
清理(Sweep / Purge)
根据对象状态依次执行
BeginDestroy()FinishDestroy()
最后将其从 GUObjectArray 全局表中删除,后释放内存(只要该对象不在永久对象池的地址范围内,就释放)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| bool UnhashUnreachableObjects(bool bUseTimeLimit, double TimeLimit)
{
while (GUnrechableObjectIndex < GUnreachableObjects.Num())
{
FUObjectItem* ObjectItem = GUnreachableObjects[GUnrechableObjectIndex++].ObjectItem;
UObject* Object = static_cast<UObject*>(ObjectItem->GetObject());
Object->ConditionalBeginDestroy();
}
}
bool IncrementalDestroyGarbage(bool bUseTimeLimit, double TimeLimit)
{
if(Object->IsReadyForFinishDestroy())
{
Object->ConditionalFinishDestroy();
}
}
FORCENOINLINE bool DestroyObjects(bool bUseTimeLimit, double TimeLimit, double StartTime)
{
GUObjectArray.FreeUObjectIndex(Object);
Object->~UObject();
GUObjectAllocator.FreeUObject(Object);
}
void FUObjectAllocator::FreeUObject(UObjectBase *Object) const
{
if (FPermanentObjectPoolExtents().Contains(Object) == false)
{
FMemory::Free(Object);
}
else
{
check(GExitPurge);
}
}
|
调参
在打包(Cooked)环境下,可以预先设置以下三个配置值,预分配对象槽位,进行性能优化。
gc.MaxObjectsInGame 预先分配好 Chunk。gc.MaxObjectsNotConsideredByGC 先预跑一次,然后去日志里找 Log: XXX objects as part of root set at end of initial load.,再将该值设置进去,这表示不需要参与垃圾回收的对象个数。gc.PreAllocateUObjectArray 提前为 UObjectArray 预留出一大块连续的槽位(FUObjectItem)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| void UObjectBaseInit()
{
int32 MaxObjectsNotConsideredByGC = 0;
int32 MaxUObjects = 2 * 1024 * 1024;
bool bPreAllocateUObjectArray = false;
if (FPlatformProperties::RequiresCookedData())
{
if (IsRunningCookOnTheFly())
{
GCreateGCClusters = false;
}
else
{
GConfig->GetInt(TEXT("/Script/Engine.GarbageCollectionSettings"), TEXT("gc.MaxObjectsNotConsideredByGC"), MaxObjectsNotConsideredByGC, GEngineIni);
}
GConfig->GetInt(TEXT("/Script/Engine.GarbageCollectionSettings"), TEXT("gc.MaxObjectsInGame"), MaxUObjects, GEngineIni);
GConfig->GetBool(TEXT("/Script/Engine.GarbageCollectionSettings"), TEXT("gc.PreAllocateUObjectArray"), bPreAllocateUObjectArray, GEngineIni);
}
if (MaxObjectsNotConsideredByGC == 0)
{
GUObjectAllocator.DisablePersistentAllocator();
}
GUObjectArray.AllocateObjectPool(MaxUObjects, MaxObjectsNotConsideredByGC, bPreAllocateUObjectArray);
}
|
可通过以下三个配置,调节垃圾回收触发速率:
gc.TimeBetweenPurgingPendingKillObjects 表示两次清理 PendingKill 对象之间等待的时间,调小这个值可以更快地触发 GC,默认 60s。gc.TimeBetweenPurgingPendingKillObjectsOnIdleServerMultiplier DS专用,没有玩家时两次 GC 的时间的倍率,默认10倍。gc.LowMemory.MemoryThresholdMB 表示内存紧张时,两次清理 PendingKill 对象之间等待的时间,就是内存紧张,可以更快触发 GC。默认 30s。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| float UEngine::GetTimeBetweenGarbageCollectionPasses(bool bHasPlayersConnected) const
{
float TimeBetweenGC = GTimeBetweenPurgingPendingKillObjects;
if (IsRunningDedicatedServer())
{
if (!bHasPlayersConnected)
{
TimeBetweenGC *= GTimeBetweenPurgingPendingKillObjectsOnIdleServerMultiplier;
}
}
if (GLowMemoryMemoryThresholdMB > 0.0)
{
TimeBetweenGC = GetLowMemoryGCTimer(TimeBetweenGC);
}
return TimeBetweenGC;
}
|