/* Force our slaves to resync with us as well. They may hopefully be able * to partially resync with us, but we can notify the replid change. */ disconnectSlaves(); cancelReplicationHandshake(0); /* Before destroying our master state, create a cached master using * our own parameters, to later PSYNC with the new master. */ if (was_master) { replicationDiscardCachedMaster(); replicationCacheMasterUsingMyself(); }
voidsyncWithMaster(connection *conn) { char tmpfile[256], *err = NULL; int dfd = -1, maxtries = 5; int psync_result;
/* If this event fired after the user turned the instance into a master * with SLAVEOF NO ONE we must just return ASAP. */ if (server.repl_state == REPL_STATE_NONE) { connClose(conn); return; }
/* Check for errors in the socket: after a non blocking connect() we * may find that the socket is in error state. */ if (connGetState(conn) != CONN_STATE_CONNECTED) { serverLog(LL_WARNING,"Error condition on socket for SYNC: %s", connGetLastError(conn)); goto error; }
/* Send a PING to check the master is able to reply without errors. */ if (server.repl_state == REPL_STATE_CONNECTING) { serverLog(LL_NOTICE,"Non blocking connect for SYNC fired the event."); /* Delete the writable event so that the readable event remains * registered and we can wait for the PONG reply. */ connSetReadHandler(conn, syncWithMaster); connSetWriteHandler(conn, NULL); server.repl_state = REPL_STATE_RECEIVE_PING_REPLY; /* Send the PING, don't check for errors at all, we have the timeout * that will take care about this. */ err = sendCommand(conn,"PING",NULL); if (err) goto write_error; return; }
/* Receive the PONG command. */ if (server.repl_state == REPL_STATE_RECEIVE_PING_REPLY) { err = receiveSynchronousResponse(conn);
/* We accept only two replies as valid, a positive +PONG reply * (we just check for "+") or an authentication error. * Note that older versions of Redis replied with "operation not * permitted" instead of using a proper error code, so we test * both. */ if (err[0] != '+' && strncmp(err,"-NOAUTH",7) != 0 && strncmp(err,"-NOPERM",7) != 0 && strncmp(err,"-ERR operation not permitted",28) != 0) { serverLog(LL_WARNING,"Error reply to PING from master: '%s'",err); sdsfree(err); goto error; } else { serverLog(LL_NOTICE, "Master replied to PING, replication can continue..."); } sdsfree(err); err = NULL; server.repl_state = REPL_STATE_SEND_HANDSHAKE; }
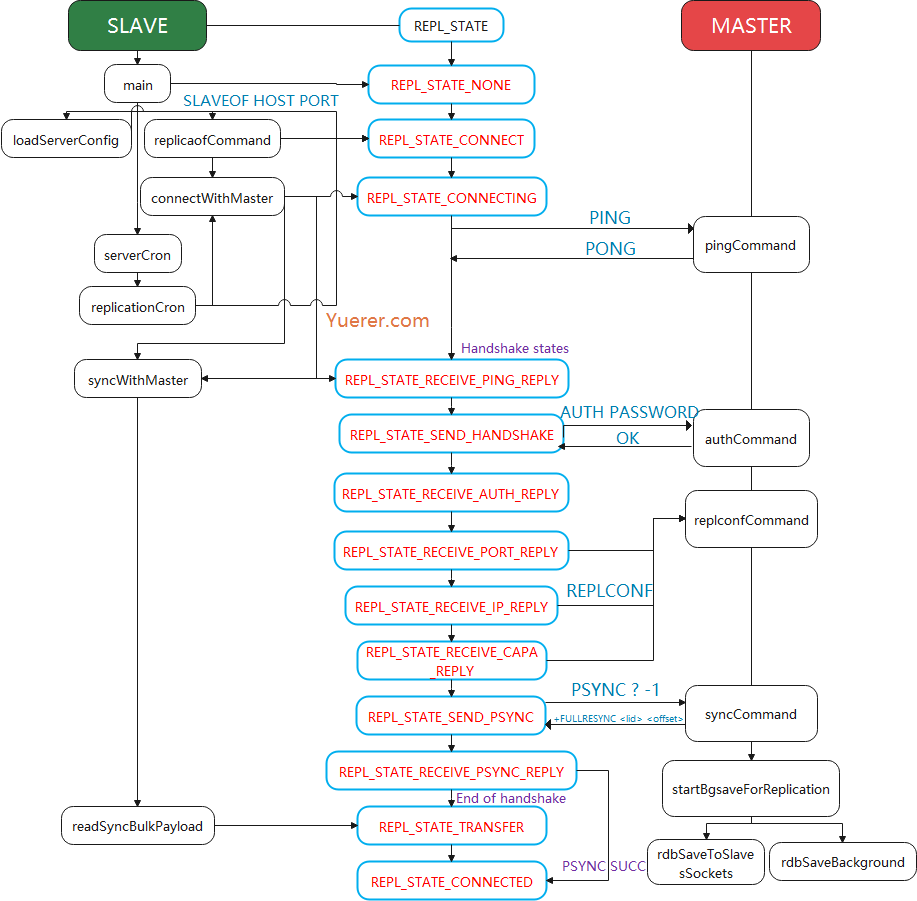
握手阶段主要是进行密码验证,将 Slave 的 IP 和 PORT 传给 Master 方便查询,同时告诉 Master 我当前的能力,比如 EOF 为我支持 无盘传输 , psync2 表示支持部分同步。
if (server.repl_state == REPL_STATE_SEND_HANDSHAKE) { /* AUTH with the master if required. */ if (server.masterauth) { char *args[3] = {"AUTH",NULL,NULL}; size_t lens[3] = {4,0,0}; int argc = 1; if (server.masteruser) { args[argc] = server.masteruser; lens[argc] = strlen(server.masteruser); argc++; } args[argc] = server.masterauth; lens[argc] = sdslen(server.masterauth); argc++; err = sendCommandArgv(conn, argc, args, lens); if (err) goto write_error; }
/* Set the slave port, so that Master's INFO command can list the * slave listening port correctly. */ { int port; if (server.slave_announce_port) port = server.slave_announce_port; elseif (server.tls_replication && server.tls_port) port = server.tls_port; else port = server.port; sds portstr = sdsfromlonglong(port); err = sendCommand(conn,"REPLCONF", "listening-port",portstr, NULL); sdsfree(portstr); if (err) goto write_error; }
/* Set the slave ip, so that Master's INFO command can list the * slave IP address port correctly in case of port forwarding or NAT. * Skip REPLCONF ip-address if there is no slave-announce-ip option set. */ if (server.slave_announce_ip) { err = sendCommand(conn,"REPLCONF", "ip-address",server.slave_announce_ip, NULL); if (err) goto write_error; }
/* Inform the master of our (slave) capabilities. * * EOF: supports EOF-style RDB transfer for diskless replication. * PSYNC2: supports PSYNC v2, so understands +CONTINUE <new repl ID>. * * The master will ignore capabilities it does not understand. */ err = sendCommand(conn,"REPLCONF", "capa","eof","capa","psync2",NULL); if (err) goto write_error;
/* Try a partial resynchonization. If we don't have a cached master * slaveTryPartialResynchronization() will at least try to use PSYNC * to start a full resynchronization so that we get the master replid * and the global offset, to try a partial resync at the next * reconnection attempt. */ if (server.repl_state == REPL_STATE_SEND_PSYNC) { if (slaveTryPartialResynchronization(conn,0) == PSYNC_WRITE_ERROR) { err = sdsnew("Write error sending the PSYNC command."); abortFailover("Write error to failover target"); goto write_error; } server.repl_state = REPL_STATE_RECEIVE_PSYNC_REPLY; return; }
psync_result = slaveTryPartialResynchronization(conn,1); if (psync_result == PSYNC_WAIT_REPLY) return; /* Try again later... */
/* Check the status of the planned failover. We expect PSYNC_CONTINUE, * but there is nothing technically wrong with a full resync which * could happen in edge cases. */ if (server.failover_state == FAILOVER_IN_PROGRESS) { if (psync_result == PSYNC_CONTINUE || psync_result == PSYNC_FULLRESYNC) { clearFailoverState(); } else { abortFailover("Failover target rejected psync request"); return; } }
/* If the master is in an transient error, we should try to PSYNC * from scratch later, so go to the error path. This happens when * the server is loading the dataset or is not connected with its * master and so forth. */ if (psync_result == PSYNC_TRY_LATER) goto error;
/* Note: if PSYNC does not return WAIT_REPLY, it will take care of * uninstalling the read handler from the file descriptor. */
if (psync_result == PSYNC_CONTINUE) { serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization."); if (server.supervised_mode == SUPERVISED_SYSTEMD) { redisCommunicateSystemd("STATUS=MASTER <-> REPLICA sync: Partial Resynchronization accepted. Ready to accept connections in read-write mode.\n"); } return; }
/* PSYNC failed or is not supported: we want our slaves to resync with us * as well, if we have any sub-slaves. The master may transfer us an * entirely different data set and we have no way to incrementally feed * our slaves after that. */ disconnectSlaves(); /* Force our slaves to resync with us as well. */ freeReplicationBacklog(); /* Don't allow our chained slaves to PSYNC. */
/* Fall back to SYNC if needed. Otherwise psync_result == PSYNC_FULLRESYNC * and the server.master_replid and master_initial_offset are * already populated. */ if (psync_result == PSYNC_NOT_SUPPORTED) { serverLog(LL_NOTICE,"Retrying with SYNC..."); if (connSyncWrite(conn,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING,"I/O error writing to MASTER: %s", strerror(errno)); goto error; } }
通过 RDB 文件传输,则先创建临时文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* Prepare a suitable temp file for bulk transfer */ if (!useDisklessLoad()) { while(maxtries--) { snprintf(tmpfile,256, "temp-%d.%ld.rdb",(int)server.unixtime,(longint)getpid()); dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644); if (dfd != -1) break; sleep(1); } if (dfd == -1) { serverLog(LL_WARNING,"Opening the temp file needed for MASTER <-> REPLICA synchronization: %s",strerror(errno)); goto error; } server.repl_transfer_tmpfile = zstrdup(tmpfile); server.repl_transfer_fd = dfd; }
/* Writing half */ if (!read_reply) { /* Initially set master_initial_offset to -1 to mark the current * master replid and offset as not valid. Later if we'll be able to do * a FULL resync using the PSYNC command we'll set the offset at the * right value, so that this information will be propagated to the * client structure representing the master into server.master. */ server.master_initial_offset = -1;
if (server.cached_master) { psync_replid = server.cached_master->replid; snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1); serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset); } else { serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)"); psync_replid = "?"; memcpy(psync_offset,"-1",3); }
/* Issue the PSYNC command, if this is a master with a failover in * progress then send the failover argument to the replica to cause it * to become a master */ if (server.failover_state == FAILOVER_IN_PROGRESS) { reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,"FAILOVER",NULL); } else { reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,NULL); }
if (reply != NULL) { serverLog(LL_WARNING,"Unable to send PSYNC to master: %s",reply); sdsfree(reply); connSetReadHandler(conn, NULL); return PSYNC_WRITE_ERROR; } return PSYNC_WAIT_REPLY; }
/* Reading half */ reply = receiveSynchronousResponse(conn); if (sdslen(reply) == 0) { /* The master may send empty newlines after it receives PSYNC * and before to reply, just to keep the connection alive. */ sdsfree(reply); return PSYNC_WAIT_REPLY; }
connSetReadHandler(conn, NULL);
if (!strncmp(reply,"+FULLRESYNC",11)) { char *replid = NULL, *offset = NULL;
/* FULL RESYNC, parse the reply in order to extract the replid * and the replication offset. */ replid = strchr(reply,' '); if (replid) { replid++; offset = strchr(replid,' '); if (offset) offset++; } if (!replid || !offset || (offset-replid-1) != CONFIG_RUN_ID_SIZE) { serverLog(LL_WARNING, "Master replied with wrong +FULLRESYNC syntax."); /* This is an unexpected condition, actually the +FULLRESYNC * reply means that the master supports PSYNC, but the reply * format seems wrong. To stay safe we blank the master * replid to make sure next PSYNCs will fail. */ memset(server.master_replid,0,CONFIG_RUN_ID_SIZE+1); } else { memcpy(server.master_replid, replid, offset-replid-1); server.master_replid[CONFIG_RUN_ID_SIZE] = '\0'; server.master_initial_offset = strtoll(offset,NULL,10); serverLog(LL_NOTICE,"Full resync from master: %s:%lld", server.master_replid, server.master_initial_offset); } /* We are going to full resync, discard the cached master structure. */ replicationDiscardCachedMaster(); sdsfree(reply); return PSYNC_FULLRESYNC; }
if (!strncmp(reply,"+CONTINUE",9)) { /* Partial resync was accepted. */ serverLog(LL_NOTICE, "Successful partial resynchronization with master.");
/* Check the new replication ID advertised by the master. If it * changed, we need to set the new ID as primary ID, and set or * secondary ID as the old master ID up to the current offset, so * that our sub-slaves will be able to PSYNC with us after a * disconnection. */ char *start = reply+10; char *end = reply+9; while(end[0] != '\r' && end[0] != '\n' && end[0] != '\0') end++; if (end-start == CONFIG_RUN_ID_SIZE) { char new[CONFIG_RUN_ID_SIZE+1]; memcpy(new,start,CONFIG_RUN_ID_SIZE); new[CONFIG_RUN_ID_SIZE] = '\0';
if (strcmp(new,server.cached_master->replid)) { /* Master ID changed. */ serverLog(LL_WARNING,"Master replication ID changed to %s",new);
/* Set the old ID as our ID2, up to the current offset+1. */ memcpy(server.replid2,server.cached_master->replid, sizeof(server.replid2)); server.second_replid_offset = server.master_repl_offset+1;
/* Update the cached master ID and our own primary ID to the * new one. */ memcpy(server.replid,new,sizeof(server.replid)); memcpy(server.cached_master->replid,new,sizeof(server.replid));
/* Disconnect all the sub-slaves: they need to be notified. */ disconnectSlaves(); } }
/* Setup the replication to continue. */ sdsfree(reply); replicationResurrectCachedMaster(conn);
/* If this instance was restarted and we read the metadata to * PSYNC from the persistence file, our replication backlog could * be still not initialized. Create it. */ if (server.repl_backlog == NULL) createReplicationBacklog(); return PSYNC_CONTINUE; }
/* If we reach this point we received either an error (since the master does * not understand PSYNC or because it is in a special state and cannot * serve our request), or an unexpected reply from the master. * * Return PSYNC_NOT_SUPPORTED on errors we don't understand, otherwise * return PSYNC_TRY_LATER if we believe this is a transient error. */
if (!strncmp(reply,"-NOMASTERLINK",13) || !strncmp(reply,"-LOADING",8)) { serverLog(LL_NOTICE, "Master is currently unable to PSYNC " "but should be in the future: %s", reply); sdsfree(reply); return PSYNC_TRY_LATER; }
if (strncmp(reply,"-ERR",4)) { /* If it's not an error, log the unexpected event. */ serverLog(LL_WARNING, "Unexpected reply to PSYNC from master: %s", reply); } else { serverLog(LL_NOTICE, "Master does not support PSYNC or is in " "error state (reply: %s)", reply); } sdsfree(reply); replicationDiscardCachedMaster(); return PSYNC_NOT_SUPPORTED; }
/* Static vars used to hold the EOF mark, and the last bytes received * from the server: when they match, we reached the end of the transfer. */ staticchar eofmark[CONFIG_RUN_ID_SIZE]; staticchar lastbytes[CONFIG_RUN_ID_SIZE]; staticint usemark = 0;
/* If repl_transfer_size == -1 we still have to read the bulk length * from the master reply. */ if (server.repl_transfer_size == -1) { if (connSyncReadLine(conn,buf,1024,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING, "I/O error reading bulk count from MASTER: %s", strerror(errno)); goto error; }
if (buf[0] == '-') { serverLog(LL_WARNING, "MASTER aborted replication with an error: %s", buf+1); goto error; } elseif (buf[0] == '\0') { /* At this stage just a newline works as a PING in order to take * the connection live. So we refresh our last interaction * timestamp. */ server.repl_transfer_lastio = server.unixtime; return; } elseif (buf[0] != '$') { serverLog(LL_WARNING,"Bad protocol from MASTER, the first byte is not '$' (we received '%s'), are you sure the host and port are right?", buf); goto error; }
/* There are two possible forms for the bulk payload. One is the * usual $<count> bulk format. The other is used for diskless transfers * when the master does not know beforehand the size of the file to * transfer. In the latter case, the following format is used: * * $EOF:<40 bytes delimiter> * * At the end of the file the announced delimiter is transmitted. The * delimiter is long and random enough that the probability of a * collision with the actual file content can be ignored. */ if (strncmp(buf+1,"EOF:",4) == 0 && strlen(buf+5) >= CONFIG_RUN_ID_SIZE) { usemark = 1; memcpy(eofmark,buf+5,CONFIG_RUN_ID_SIZE); memset(lastbytes,0,CONFIG_RUN_ID_SIZE); /* Set any repl_transfer_size to avoid entering this code path * at the next call. */ server.repl_transfer_size = 0; serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF %s", use_diskless_load? "to parser":"to disk"); } else { usemark = 0; server.repl_transfer_size = strtol(buf+1,NULL,10); serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: receiving %lld bytes from master %s", (longlong) server.repl_transfer_size, use_diskless_load? "to parser":"to disk"); } return; }
if (!use_diskless_load) { /* Read the data from the socket, store it to a file and search * for the EOF. */ if (usemark) { readlen = sizeof(buf); } else { left = server.repl_transfer_size - server.repl_transfer_read; readlen = (left < (signed)sizeof(buf)) ? left : (signed)sizeof(buf); }
nread = connRead(conn,buf,readlen); if (nread <= 0) { if (connGetState(conn) == CONN_STATE_CONNECTED) { /* equivalent to EAGAIN */ return; } serverLog(LL_WARNING,"I/O error trying to sync with MASTER: %s", (nread == -1) ? strerror(errno) : "connection lost"); cancelReplicationHandshake(1); return; } atomicIncr(server.stat_net_input_bytes, nread);
/* When a mark is used, we want to detect EOF asap in order to avoid * writing the EOF mark into the file... */ int eof_reached = 0;
if (usemark) { /* Update the last bytes array, and check if it matches our * delimiter. */ if (nread >= CONFIG_RUN_ID_SIZE) { memcpy(lastbytes,buf+nread-CONFIG_RUN_ID_SIZE, CONFIG_RUN_ID_SIZE); } else { int rem = CONFIG_RUN_ID_SIZE-nread; memmove(lastbytes,lastbytes+nread,rem); memcpy(lastbytes+rem,buf,nread); } if (memcmp(lastbytes,eofmark,CONFIG_RUN_ID_SIZE) == 0) eof_reached = 1; }
/* Update the last I/O time for the replication transfer (used in * order to detect timeouts during replication), and write what we * got from the socket to the dump file on disk. */ server.repl_transfer_lastio = server.unixtime; if ((nwritten = write(server.repl_transfer_fd,buf,nread)) != nread) { serverLog(LL_WARNING, "Write error or short write writing to the DB dump file " "needed for MASTER <-> REPLICA synchronization: %s", (nwritten == -1) ? strerror(errno) : "short write"); goto error; } server.repl_transfer_read += nread;
/* Delete the last 40 bytes from the file if we reached EOF. */ if (usemark && eof_reached) { if (ftruncate(server.repl_transfer_fd, server.repl_transfer_read - CONFIG_RUN_ID_SIZE) == -1) { serverLog(LL_WARNING, "Error truncating the RDB file received from the master " "for SYNC: %s", strerror(errno)); goto error; } }
/* Sync data on disk from time to time, otherwise at the end of the * transfer we may suffer a big delay as the memory buffers are copied * into the actual disk. */ if (server.repl_transfer_read >= server.repl_transfer_last_fsync_off + REPL_MAX_WRITTEN_BEFORE_FSYNC) { off_t sync_size = server.repl_transfer_read - server.repl_transfer_last_fsync_off; rdb_fsync_range(server.repl_transfer_fd, server.repl_transfer_last_fsync_off, sync_size); server.repl_transfer_last_fsync_off += sync_size; }
/* Check if the transfer is now complete */ if (!usemark) { if (server.repl_transfer_read == server.repl_transfer_size) eof_reached = 1; }
/* If the transfer is yet not complete, we need to read more, so * return ASAP and wait for the handler to be called again. */ if (!eof_reached) return; }
/* We reach this point in one of the following cases: * * 1. The replica is using diskless replication, that is, it reads data * directly from the socket to the Redis memory, without using * a temporary RDB file on disk. In that case we just block and * read everything from the socket. * * 2. Or when we are done reading from the socket to the RDB file, in * such case we want just to read the RDB file in memory. */ serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Flushing old data");
/* We need to stop any AOF rewriting child before flusing and parsing * the RDB, otherwise we'll create a copy-on-write disaster. */ if (server.aof_state != AOF_OFF) stopAppendOnly();
/* When diskless RDB loading is used by replicas, it may be configured * in order to save the current DB instead of throwing it away, * so that we can restore it in case of failed transfer. */
/* Ensure background save doesn't overwrite synced data */ if (server.child_type == CHILD_TYPE_RDB) { serverLog(LL_NOTICE, "Replica is about to load the RDB file received from the " "master, but there is a pending RDB child running. " "Killing process %ld and removing its temp file to avoid " "any race", (long) server.child_pid); killRDBChild(); }
/* Make sure the new file (also used for persistence) is fully synced * (not covered by earlier calls to rdb_fsync_range). */ if (fsync(server.repl_transfer_fd) == -1) { serverLog(LL_WARNING, "Failed trying to sync the temp DB to disk in " "MASTER <-> REPLICA synchronization: %s", strerror(errno)); cancelReplicationHandshake(1); return; }
/* Rename rdb like renaming rewrite aof asynchronously. */ int old_rdb_fd = open(server.rdb_filename,O_RDONLY|O_NONBLOCK); if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) { serverLog(LL_WARNING, "Failed trying to rename the temp DB into %s in " "MASTER <-> REPLICA synchronization: %s", server.rdb_filename, strerror(errno)); cancelReplicationHandshake(1); if (old_rdb_fd != -1) close(old_rdb_fd); return; } /* Close old rdb asynchronously. */ if (old_rdb_fd != -1) bioCreateCloseJob(old_rdb_fd);
if (rdbLoad(server.rdb_filename,&rsi,RDBFLAGS_REPLICATION) != C_OK) { serverLog(LL_WARNING, "Failed trying to load the MASTER synchronization " "DB from disk"); cancelReplicationHandshake(1); if (server.rdb_del_sync_files && allPersistenceDisabled()) { serverLog(LL_NOTICE,"Removing the RDB file obtained from " "the master. This replica has persistence " "disabled"); bg_unlink(server.rdb_filename); } /* Note that there's no point in restarting the AOF on sync failure, it'll be restarted when sync succeeds or replica promoted. */ return; }
/* Cleanup. */ if (server.rdb_del_sync_files && allPersistenceDisabled()) { serverLog(LL_NOTICE,"Removing the RDB file obtained from " "the master. This replica has persistence " "disabled"); bg_unlink(server.rdb_filename); }
if (use_diskless_load && server.repl_diskless_load == REPL_DISKLESS_LOAD_SWAPDB) { /* Create a backup of server.db[] and initialize to empty * dictionaries. */ diskless_load_backup = disklessLoadMakeBackup(); } /* We call to emptyDb even in case of REPL_DISKLESS_LOAD_SWAPDB * (Where disklessLoadMakeBackup left server.db empty) because we * want to execute all the auxiliary logic of emptyDb (Namely, * fire module events) */ emptyDb(-1,empty_db_flags,replicationEmptyDbCallback);
/* Before loading the DB into memory we need to delete the readable * handler, otherwise it will get called recursively since * rdbLoad() will call the event loop to process events from time to * time for non blocking loading. */ connSetReadHandler(conn, NULL); serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Loading DB in memory"); rdbSaveInfo rsi = RDB_SAVE_INFO_INIT; if (use_diskless_load) { rio rdb; rioInitWithConn(&rdb,conn,server.repl_transfer_size);
/* Put the socket in blocking mode to simplify RDB transfer. * We'll restore it when the RDB is received. */ connBlock(conn); connRecvTimeout(conn, server.repl_timeout*1000); startLoading(server.repl_transfer_size, RDBFLAGS_REPLICATION);
if (rdbLoadRio(&rdb,RDBFLAGS_REPLICATION,&rsi) != C_OK) { /* RDB loading failed. */ stopLoading(0); serverLog(LL_WARNING, "Failed trying to load the MASTER synchronization DB " "from socket"); cancelReplicationHandshake(1); rioFreeConn(&rdb, NULL);
/* Remove the half-loaded data in case we started with * an empty replica. */ emptyDb(-1,empty_db_flags,replicationEmptyDbCallback);
if (server.repl_diskless_load == REPL_DISKLESS_LOAD_SWAPDB) { /* Restore the backed up databases. */ disklessLoadRestoreBackup(diskless_load_backup); }
/* Note that there's no point in restarting the AOF on SYNC * failure, it'll be restarted when sync succeeds or the replica * gets promoted. */ return; }
/* RDB loading succeeded if we reach this point. */ if (server.repl_diskless_load == REPL_DISKLESS_LOAD_SWAPDB) { /* Delete the backup databases we created before starting to load * the new RDB. Now the RDB was loaded with success so the old * data is useless. */ disklessLoadDiscardBackup(diskless_load_backup, empty_db_flags); }
/* Verify the end mark is correct. */ if (usemark) { if (!rioRead(&rdb,buf,CONFIG_RUN_ID_SIZE) || memcmp(buf,eofmark,CONFIG_RUN_ID_SIZE) != 0) { stopLoading(0); serverLog(LL_WARNING,"Replication stream EOF marker is broken"); cancelReplicationHandshake(1); rioFreeConn(&rdb, NULL); return; } }
stopLoading(1);
/* Cleanup and restore the socket to the original state to continue * with the normal replication. */ rioFreeConn(&rdb, NULL); connNonBlock(conn); connRecvTimeout(conn,0);
voidreplicationCron(void) { /* Non blocking connection timeout? */ if (server.masterhost && (server.repl_state == REPL_STATE_CONNECTING || slaveIsInHandshakeState()) && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { serverLog(LL_WARNING,"Timeout connecting to the MASTER..."); cancelReplicationHandshake(1); }
/* Bulk transfer I/O timeout? */ if (server.masterhost && server.repl_state == REPL_STATE_TRANSFER && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { serverLog(LL_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value."); cancelReplicationHandshake(1); }
/* Timed out master when we are an already connected slave? */ if (server.masterhost && server.repl_state == REPL_STATE_CONNECTED && (time(NULL)-server.master->lastinteraction) > server.repl_timeout) { serverLog(LL_WARNING,"MASTER timeout: no data nor PING received..."); freeClient(server.master); }
/* Check if we should connect to a MASTER */ if (server.repl_state == REPL_STATE_CONNECT) { serverLog(LL_NOTICE,"Connecting to MASTER %s:%d", server.masterhost, server.masterport); connectWithMaster(); }
/* Send ACK to master from time to time. * Note that we do not send periodic acks to masters that don't * support PSYNC and replication offsets. */ if (server.masterhost && server.master && !(server.master->flags & CLIENT_PRE_PSYNC)) replicationSendAck(); }
voidsyncCommand(client *c) { .... /* Try a partial resynchronization if this is a PSYNC command. * If it fails, we continue with usual full resynchronization, however * when this happens masterTryPartialResynchronization() already * replied with: * * +FULLRESYNC <replid> <offset> * * So the slave knows the new replid and offset to try a PSYNC later * if the connection with the master is lost. */ if (!strcasecmp(c->argv[0]->ptr,"psync")) { if (masterTryPartialResynchronization(c) == C_OK) { server.stat_sync_partial_ok++; return; /* No full resync needed, return. */ } } else { /* If a slave uses SYNC, we are dealing with an old implementation * of the replication protocol (like redis-cli --slave). Flag the client * so that we don't expect to receive REPLCONF ACK feedbacks. */ c->flags |= CLIENT_PRE_PSYNC; }
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START; if (server.repl_disable_tcp_nodelay) connDisableTcpNoDelay(c->conn); /* Non critical if it fails. */ c->repldbfd = -1; c->flags |= CLIENT_SLAVE; listAddNodeTail(server.slaves,c);
/* Create the replication backlog if needed. */ if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) { /* When we create the backlog from scratch, we always use a new * replication ID and clear the ID2, since there is no valid * past history. */ changeReplicationId(); clearReplicationId2(); createReplicationBacklog(); serverLog(LL_NOTICE,"Replication backlog created, my new " "replication IDs are '%s' and '%s'", server.replid, server.replid2); }
/* CASE 1: BGSAVE is in progress, with disk target. */ if (server.child_type == CHILD_TYPE_RDB && server.rdb_child_type == RDB_CHILD_TYPE_DISK) { /* Ok a background save is in progress. Let's check if it is a good * one for replication, i.e. if there is another slave that is * registering differences since the server forked to save. */ client *slave; listNode *ln; listIter li;
listRewind(server.slaves,&li); while((ln = listNext(&li))) { slave = ln->value; /* If the client needs a buffer of commands, we can't use * a replica without replication buffer. */ if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END && (!(slave->flags & CLIENT_REPL_RDBONLY) || (c->flags & CLIENT_REPL_RDBONLY))) break; } /* To attach this slave, we check that it has at least all the * capabilities of the slave that triggered the current BGSAVE. */ if (ln && ((c->slave_capa & slave->slave_capa) == slave->slave_capa)) { /* Perfect, the server is already registering differences for * another slave. Set the right state, and copy the buffer. * We don't copy buffer if clients don't want. */ if (!(c->flags & CLIENT_REPL_RDBONLY)) copyClientOutputBuffer(c,slave); replicationSetupSlaveForFullResync(c,slave->psync_initial_offset); serverLog(LL_NOTICE,"Waiting for end of BGSAVE for SYNC"); } else { /* No way, we need to wait for the next BGSAVE in order to * register differences. */ serverLog(LL_NOTICE,"Can't attach the replica to the current BGSAVE. Waiting for next BGSAVE for SYNC"); }
/* CASE 2: BGSAVE is in progress, with socket target. */ } elseif (server.child_type == CHILD_TYPE_RDB && server.rdb_child_type == RDB_CHILD_TYPE_SOCKET) { /* There is an RDB child process but it is writing directly to * children sockets. We need to wait for the next BGSAVE * in order to synchronize. */ serverLog(LL_NOTICE,"Current BGSAVE has socket target. Waiting for next BGSAVE for SYNC");
/* CASE 3: There is no BGSAVE is progress. */ } else { if (server.repl_diskless_sync && (c->slave_capa & SLAVE_CAPA_EOF) && server.repl_diskless_sync_delay) { /* Diskless replication RDB child is created inside * replicationCron() since we want to delay its start a * few seconds to wait for more slaves to arrive. */ serverLog(LL_NOTICE,"Delay next BGSAVE for diskless SYNC"); } else { /* We don't have a BGSAVE in progress, let's start one. Diskless * or disk-based mode is determined by replica's capacity. */ if (!hasActiveChildProcess()) { startBgsaveForReplication(c->slave_capa); } else { serverLog(LL_NOTICE, "No BGSAVE in progress, but another BG operation is active. " "BGSAVE for replication delayed"); } } }
intstartBgsaveForReplication(int mincapa) { int retval; int socket_target = server.repl_diskless_sync && (mincapa & SLAVE_CAPA_EOF); listIter li; listNode *ln;
serverLog(LL_NOTICE,"Starting BGSAVE for SYNC with target: %s", socket_target ? "replicas sockets" : "disk");
rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); /* Only do rdbSave* when rsiptr is not NULL, * otherwise slave will miss repl-stream-db. */ if (rsiptr) { if (socket_target) retval = rdbSaveToSlavesSockets(rsiptr); else retval = rdbSaveBackground(server.rdb_filename,rsiptr); } else { serverLog(LL_WARNING,"BGSAVE for replication: replication information not available, can't generate the RDB file right now. Try later."); retval = C_ERR; }
/* If the target is socket, rdbSaveToSlavesSockets() already setup * the slaves for a full resync. Otherwise for disk target do it now.*/ if (!socket_target) { listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value;
/* Spawn an RDB child that writes the RDB to the sockets of the slaves * that are currently in SLAVE_STATE_WAIT_BGSAVE_START state. */ intrdbSaveToSlavesSockets(rdbSaveInfo *rsi) { listNode *ln; listIter li; pid_t childpid; int pipefds[2], rdb_pipe_write, safe_to_exit_pipe;
server.rdb_pipe_read = pipefds[0]; /* read end */ rdb_pipe_write = pipefds[1]; /* write end */ anetNonBlock(NULL, server.rdb_pipe_read);
safe_to_exit_pipe = pipefds[0]; /* read end */ server.rdb_child_exit_pipe = pipefds[1]; /* write end */
/* Collect the connections of the replicas we want to transfer * the RDB to, which are i WAIT_BGSAVE_START state. */ server.rdb_pipe_conns = zmalloc(sizeof(connection *)*listLength(server.slaves)); server.rdb_pipe_numconns = 0; server.rdb_pipe_numconns_writing = 0; listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value; if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) { server.rdb_pipe_conns[server.rdb_pipe_numconns++] = slave->conn; replicationSetupSlaveForFullResync(slave,getPsyncInitialOffset()); } }
/* Create the child process. */ if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) { /* Child */ int retval, dummy; rio rdb;
if (retval == C_OK) { sendChildCowInfo(CHILD_INFO_TYPE_RDB_COW_SIZE, "RDB"); }
rioFreeFd(&rdb); /* wake up the reader, tell it we're done. */ close(rdb_pipe_write); close(server.rdb_child_exit_pipe); /* close write end so that we can detect the close on the parent. */ /* hold exit until the parent tells us it's safe. we're not expecting * to read anything, just get the error when the pipe is closed. */ dummy = read(safe_to_exit_pipe, pipefds, 1); UNUSED(dummy); exitFromChild((retval == C_OK) ? 0 : 1);
} else { /* Parent */ close(safe_to_exit_pipe); if (childpid == -1) { serverLog(LL_WARNING,"Can't save in background: fork: %s", strerror(errno));
/* Undo the state change. The caller will perform cleanup on * all the slaves in BGSAVE_START state, but an early call to * replicationSetupSlaveForFullResync() turned it into BGSAVE_END */ listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value; if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END) { slave->replstate = SLAVE_STATE_WAIT_BGSAVE_START; } } close(rdb_pipe_write); close(server.rdb_pipe_read); zfree(server.rdb_pipe_conns); server.rdb_pipe_conns = NULL; server.rdb_pipe_numconns = 0; server.rdb_pipe_numconns_writing = 0; } else { serverLog(LL_NOTICE,"Background RDB transfer started by pid %ld", (long) childpid); server.rdb_save_time_start = time(NULL); server.rdb_child_type = RDB_CHILD_TYPE_SOCKET; close(rdb_pipe_write); /* close write in parent so that it can detect the close on the child. */ if (aeCreateFileEvent(server.el, server.rdb_pipe_read, AE_READABLE, rdbPipeReadHandler,NULL) == AE_ERR) { serverPanic("Unrecoverable error creating server.rdb_pipe_read file event."); } } return (childpid == -1) ? C_ERR : C_OK; } return C_OK; /* Unreached. */ }