/* Initialize the data structures needed for threaded I/O. */ voidinitThreadedIO(void) { server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread: * we'll handle I/O directly from the main thread. */ if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) { serverLog(LL_WARNING,"Fatal: too many I/O threads configured. " "The maximum number is %d.", IO_THREADS_MAX_NUM); exit(1); }
/* Spawn and initialize the I/O threads. */ for (int i = 0; i < server.io_threads_num; i++) { /* Things we do for all the threads including the main thread. */ io_threads_list[i] = listCreate(); if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */ pthread_t tid; pthread_mutex_init(&io_threads_mutex[i],NULL); setIOPendingCount(i, 0); pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */ if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize IO thread."); exit(1); } io_threads[i] = tid; } }
staticinlinevoidsetIOPendingCount(int i, unsignedlong count) { atomicSetWithSync(io_threads_pending[i], count); }
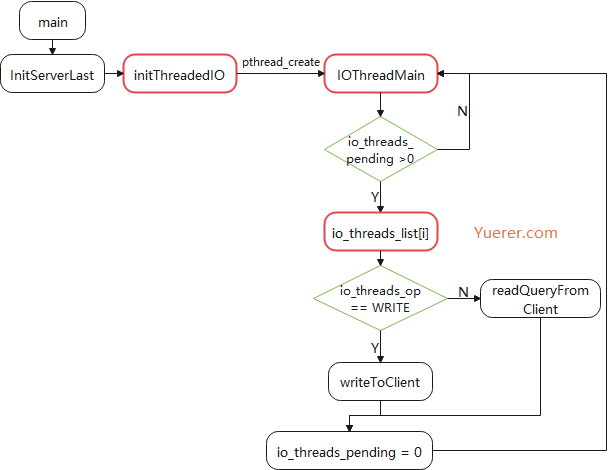
void *IOThreadMain(void *myid) { /* The ID is the thread number (from 0 to server.iothreads_num-1), and is * used by the thread to just manipulate a single sub-array of clients. */ long id = (unsignedlong)myid; char thdname[16];
while(1) { /* Wait for start */ for (int j = 0; j < 1000000; j++) { if (getIOPendingCount(id) != 0) break; }
/* Give the main thread a chance to stop this thread. */ if (getIOPendingCount(id) == 0) { pthread_mutex_lock(&io_threads_mutex[id]); pthread_mutex_unlock(&io_threads_mutex[id]); continue; }
serverAssert(getIOPendingCount(id) != 0);
/* Process: note that the main thread will never touch our list * before we drop the pending count to 0. */ listIter li; listNode *ln; listRewind(io_threads_list[id],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); if (io_threads_op == IO_THREADS_OP_WRITE) { writeToClient(c,0); } elseif (io_threads_op == IO_THREADS_OP_READ) { readQueryFromClient(c->conn); } else { serverPanic("io_threads_op value is unknown"); } } listEmpty(io_threads_list[id]); setIOPendingCount(id, 0); } }
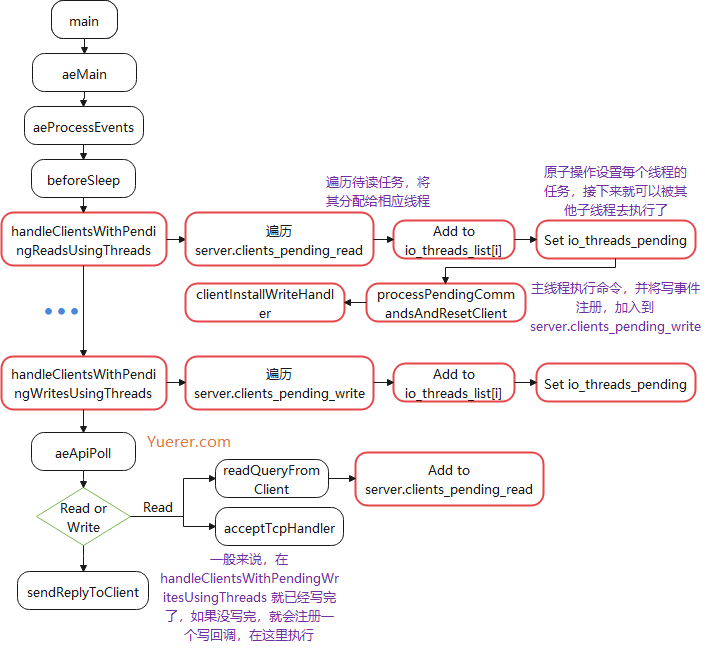
inthandleClientsWithPendingReadsUsingThreads(void) { if (!server.io_threads_active || !server.io_threads_do_reads) return0; int processed = listLength(server.clients_pending_read); if (processed == 0) return0;
/* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; }
/* Give the start condition to the waiting threads, by setting the * start condition atomic var. */ io_threads_op = IO_THREADS_OP_READ; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); }
/* Also use the main thread to process a slice of clients. */ listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); readQueryFromClient(c->conn); } listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */ while(1) { unsignedlong pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; }
/* Run the list of clients again to process the new buffers. */ while(listLength(server.clients_pending_read)) { ln = listFirst(server.clients_pending_read); client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_READ; listDelNode(server.clients_pending_read,ln);
if (processPendingCommandsAndResetClient(c) == C_ERR) { /* If the client is no longer valid, we avoid * processing the client later. So we just go * to the next. */ continue; }
processInputBuffer(c);
/* We may have pending replies if a thread readQueryFromClient() produced * replies and did not install a write handler (it can't). */ if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c)) clientInstallWriteHandler(c); }
/* Update processed count on server */ server.stat_io_reads_processed += processed;
return processed; }
handleClientsWithPendingWritesUsingThreads
写操作,检查一下 I/O线程 是否开启,当任务量少的时候,会通过 lock(mutex) 临时阻塞子线程,因为子线程是一个死循环,就算没有任务也会占满 CPU 。如果没有写完,则会设置写回调,注册到 epoll 中,下次由主线程去写。
intstopThreadedIOIfNeeded(void) { int pending = listLength(server.clients_pending_write);
/* Return ASAP if IO threads are disabled (single threaded mode). */ if (server.io_threads_num == 1) return1;
if (pending < (server.io_threads_num*2)) { if (server.io_threads_active) stopThreadedIO(); return1; } else { return0; } }
inthandleClientsWithPendingWritesUsingThreads(void) { int processed = listLength(server.clients_pending_write); if (processed == 0) return0; /* Return ASAP if there are no clients. */
/* If I/O threads are disabled or we have few clients to serve, don't * use I/O threads, but the boring synchronous code. */ if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) { return handleClientsWithPendingWrites(); }
/* Start threads if needed. */ if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */ listIter li; listNode *ln; listRewind(server.clients_pending_write,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since * they are going to be closed ASAP. */ if (c->flags & CLIENT_CLOSE_ASAP) { listDelNode(server.clients_pending_write, ln); continue; }
int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; }
/* Give the start condition to the waiting threads, by setting the * start condition atomic var. */ io_threads_op = IO_THREADS_OP_WRITE; for (int j = 1; j < server.io_threads_num; j++) { int count = listLength(io_threads_list[j]); setIOPendingCount(j, count); }
/* Also use the main thread to process a slice of clients. */ listRewind(io_threads_list[0],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); writeToClient(c,0); } listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */ while(1) { unsignedlong pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j); if (pending == 0) break; }
/* Run the list of clients again to install the write handler where * needed. */ listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln);
/* Install the write handler if there are pending writes in some * of the clients. */ if (clientHasPendingReplies(c) && connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) { freeClientAsync(c); } } listEmpty(server.clients_pending_write);
/* Update processed count on server */ server.stat_io_writes_processed += processed;
voidbioInit(void) { pthread_attr_t attr; pthread_t thread; size_t stacksize; int j;
/* Initialization of state vars and objects */ for (j = 0; j < BIO_NUM_OPS; j++) { pthread_mutex_init(&bio_mutex[j],NULL); pthread_cond_init(&bio_newjob_cond[j],NULL); pthread_cond_init(&bio_step_cond[j],NULL); bio_jobs[j] = listCreate(); bio_pending[j] = 0; }
/* Set the stack size as by default it may be small in some system */ pthread_attr_init(&attr); pthread_attr_getstacksize(&attr,&stacksize); if (!stacksize) stacksize = 1; /* The world is full of Solaris Fixes */ while (stacksize < REDIS_THREAD_STACK_SIZE) stacksize *= 2; pthread_attr_setstacksize(&attr, stacksize);
/* Ready to spawn our threads. We use the single argument the thread * function accepts in order to pass the job ID the thread is * responsible of. */ for (j = 0; j < BIO_NUM_OPS; j++) { void *arg = (void*)(unsignedlong) j; if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs."); exit(1); } bio_threads[j] = thread; } }
structbio_job { time_t time; /* Time at which the job was created. */ /* Job specific arguments.*/ int fd; /* Fd for file based background jobs */ lazy_free_fn *free_fn; /* Function that will free the provided arguments */ void *free_args[]; /* List of arguments to be passed to the free function */ };
/* Check that the type is within the right interval. */ if (type >= BIO_NUM_OPS) { serverLog(LL_WARNING, "Warning: bio thread started with wrong type %lu",type); returnNULL; }
switch (type) { case BIO_CLOSE_FILE: redis_set_thread_title("bio_close_file"); break; case BIO_AOF_FSYNC: redis_set_thread_title("bio_aof_fsync"); break; case BIO_LAZY_FREE: redis_set_thread_title("bio_lazy_free"); break; }
redisSetCpuAffinity(server.bio_cpulist);
makeThreadKillable();
pthread_mutex_lock(&bio_mutex[type]); /* Block SIGALRM so we are sure that only the main thread will * receive the watchdog signal. */ sigemptyset(&sigset); sigaddset(&sigset, SIGALRM); if (pthread_sigmask(SIG_BLOCK, &sigset, NULL)) serverLog(LL_WARNING, "Warning: can't mask SIGALRM in bio.c thread: %s", strerror(errno));
while(1) { listNode *ln;
/* The loop always starts with the lock hold. */ if (listLength(bio_jobs[type]) == 0) { pthread_cond_wait(&bio_newjob_cond[type],&bio_mutex[type]); continue; } /* Pop the job from the queue. */ ln = listFirst(bio_jobs[type]); job = ln->value; /* It is now possible to unlock the background system as we know have * a stand alone job structure to process.*/ pthread_mutex_unlock(&bio_mutex[type]);
/* Process the job accordingly to its type. */ if (type == BIO_CLOSE_FILE) { close(job->fd); } elseif (type == BIO_AOF_FSYNC) { redis_fsync(job->fd); } elseif (type == BIO_LAZY_FREE) { job->free_fn(job->free_args); } else { serverPanic("Wrong job type in bioProcessBackgroundJobs()."); } zfree(job);
/* Lock again before reiterating the loop, if there are no longer * jobs to process we'll block again in pthread_cond_wait(). */ pthread_mutex_lock(&bio_mutex[type]); listDelNode(bio_jobs[type],ln); bio_pending[type]--;
/* Unblock threads blocked on bioWaitStepOfType() if any. */ pthread_cond_broadcast(&bio_step_cond[type]); } }
关闭文件描述符
关闭文件描述符,有可能会删除掉文件,引起阻塞。因为 Redis 实现的时候会通过 rename 覆盖掉原有文件,将文件描述符的关闭交给 bio 子线程避免阻塞。
voidpropagate(struct redisCommand *cmd, int dbid, robj **argv, int argc, int flags) { if (!server.replication_allowed) return;
/* Propagate a MULTI request once we encounter the first command which * is a write command. * This way we'll deliver the MULTI/..../EXEC block as a whole and * both the AOF and the replication link will have the same consistency * and atomicity guarantees. */ if (server.in_exec && !server.propagate_in_transaction) execCommandPropagateMulti(dbid);
/* This needs to be unreachable since the dataset should be fixed during * client pause, otherwise data may be lossed during a failover. */ serverAssert(!(areClientsPaused() && !server.client_pause_in_transaction));
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF) feedAppendOnlyFile(cmd,dbid,argv,argc); if (flags & PROPAGATE_REPL) replicationFeedSlaves(server.slaves,dbid,argv,argc); }
voidfeedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) { sds buf = sdsempty(); /* The DB this command was targeting is not the same as the last command * we appended. To issue a SELECT command is needed. */ if (dictid != server.aof_selected_db) { char seldb[64];
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand || cmd->proc == expireatCommand) { /* Translate EXPIRE/PEXPIRE/EXPIREAT into PEXPIREAT */ buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]); } elseif (cmd->proc == setCommand && argc > 3) { robj *pxarg = NULL; /* When SET is used with EX/PX argument setGenericCommand propagates them with PX millisecond argument. * So since the command arguments are re-written there, we can rely here on the index of PX being 3. */ if (!strcasecmp(argv[3]->ptr, "px")) { pxarg = argv[4]; } /* For AOF we convert SET key value relative time in milliseconds to SET key value absolute time in * millisecond. Whenever the condition is true it implies that original SET has been transformed * to SET PX with millisecond time argument so we do not need to worry about unit here.*/ if (pxarg) { robj *millisecond = getDecodedObject(pxarg); longlong when = strtoll(millisecond->ptr,NULL,10); when += mstime();
decrRefCount(millisecond);
robj *newargs[5]; newargs[0] = argv[0]; newargs[1] = argv[1]; newargs[2] = argv[2]; newargs[3] = shared.pxat; newargs[4] = createStringObjectFromLongLong(when); buf = catAppendOnlyGenericCommand(buf,5,newargs); decrRefCount(newargs[4]); } else { buf = catAppendOnlyGenericCommand(buf,argc,argv); } } else { /* All the other commands don't need translation or need the * same translation already operated in the command vector * for the replication itself. */ buf = catAppendOnlyGenericCommand(buf,argc,argv); }
/* Append to the AOF buffer. This will be flushed on disk just before * of re-entering the event loop, so before the client will get a * positive reply about the operation performed. */ if (server.aof_state == AOF_ON) server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
/* If a background append only file rewriting is in progress we want to * accumulate the differences between the child DB and the current one * in a buffer, so that when the child process will do its work we * can append the differences to the new append only file. */ if (server.child_type == CHILD_TYPE_AOF) aofRewriteBufferAppend((unsignedchar*)buf,sdslen(buf));
sdsfree(buf); }
flushAppendOnlyFile
AOF日志同步到硬盘的策略有三种,第一种不同步,由内核自己决定Flush时机,另一种每次都同步,但是 fsync 是会阻塞的,因此还有第三种每秒同步,通过 BIO 子线程,每秒去同步 fsync 一次,其实说是 fsync 也不准确,在 Linux 下用的是 fdatasync 省去了写文件的元数据开销。
if (hasActiveChildProcess()) return C_ERR; if (aofCreatePipes() != C_OK) return C_ERR; if ((childpid = redisFork(CHILD_TYPE_AOF)) == 0) { char tmpfile[256];
/* Child */ redisSetProcTitle("redis-aof-rewrite"); redisSetCpuAffinity(server.aof_rewrite_cpulist); snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid()); if (rewriteAppendOnlyFile(tmpfile) == C_OK) { sendChildCowInfo(CHILD_INFO_TYPE_AOF_COW_SIZE, "AOF rewrite"); exitFromChild(0); } else { exitFromChild(1); } } else { /* Parent */ if (childpid == -1) { serverLog(LL_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno)); aofClosePipes(); return C_ERR; } serverLog(LL_NOTICE, "Background append only file rewriting started by pid %ld",(long) childpid); server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL);
/* We set appendseldb to -1 in order to force the next call to the * feedAppendOnlyFile() to issue a SELECT command, so the differences * accumulated by the parent into server.aof_rewrite_buf will start * with a SELECT statement and it will be safe to merge. */ server.aof_selected_db = -1; replicationScriptCacheFlush(); return C_OK; } return C_OK; /* unreached */ }
voidcheckChildrenDone(void) { int statloc; pid_t pid;
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) { int exitcode = WEXITSTATUS(statloc); int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
/* sigKillChildHandler catches the signal and calls exit(), but we * must make sure not to flag lastbgsave_status, etc incorrectly. * We could directly terminate the child process via SIGUSR1 * without handling it, but in this case Valgrind will log an * annoying error. */ if (exitcode == SERVER_CHILD_NOERROR_RETVAL) { bysignal = SIGUSR1; exitcode = 1; }
if (pid == -1) { serverLog(LL_WARNING,"wait3() returned an error: %s. " "child_type: %s, child_pid = %d", strerror(errno), strChildType(server.child_type), (int) server.child_pid); } elseif (pid == server.child_pid) { if (server.child_type == CHILD_TYPE_RDB) { backgroundSaveDoneHandler(exitcode, bysignal); } elseif (server.child_type == CHILD_TYPE_AOF) { backgroundRewriteDoneHandler(exitcode, bysignal); } elseif (server.child_type == CHILD_TYPE_MODULE) { ModuleForkDoneHandler(exitcode, bysignal); } else { serverPanic("Unknown child type %d for child pid %d", server.child_type, server.child_pid); exit(1); } if (!bysignal && exitcode == 0) receiveChildInfo(); resetChildState(); } else { if (!ldbRemoveChild(pid)) { serverLog(LL_WARNING, "Warning, detected child with unmatched pid: %ld", (long) pid); } }
/* start any pending forks immediately. */ replicationStartPendingFork(); } }
/* If there is not a background saving/rewrite in progress check if * we have to save/rewrite now. */ for (j = 0; j < server.saveparamslen; j++) { structsaveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes, * the given amount of seconds, and if the latest bgsave was * successful or if, in case of an error, at least * CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */ if (server.dirty >= sp->changes && server.unixtime-server.lastsave > sp->seconds && (server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) { serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds); rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); rdbSaveBackground(server.rdb_filename,rsiptr); break; } }